
Contents
- Machine Learning (ML): An In-Depth Guide to How It Works, Types, Applications, and Benefits
- What is Machine Learning (ML)?
- A Brief History of Machine Learning
- Types of Machine Learning
- How Machine Learning Works: Algorithms, Training, and Evaluation
- Common ML Algorithms and Models
- Data Preprocessing and Feature Engineering
- Model Training
- Evaluation Metrics
- Example – Putting it Together:
- Applications of Machine Learning in the Real World
- Recent Advancements in Machine Learning
- Ethical Considerations in Machine Learning
- The Future of Machine Learning
Machine Learning (ML): An In-Depth Guide to How It Works, Types, Applications, and Benefits
Machine Learning (ML) is everywhere today – from the recommended movies on your streaming service to the AI chatbots answering customer questions. It has become a cornerstone of modern technology, empowering computers to learn from data and make decisions with minimal human intervention. In this comprehensive guide, we’ll explore what Machine Learning is, how it evolved, the types of ML algorithms, the technical workings of ML (like model training and evaluation), and its real-world applications across industries. We’ll also discuss recent advancements (such as deep learning, AutoML, and transfer learning), important ethical considerations (privacy, fairness, explainability), and the future trends that are shaping this exciting field.
Our aim is to provide a balanced, educational, and conversational overview. Whether you’re a student just starting or a professional looking to refresh your knowledge, this guide will help you understand the ins and outs of Machine Learning and how it is transforming the world around us.
What is Machine Learning (ML)?

Machine Learning is generally defined as a subset of Artificial Intelligence (AI) that enables computers to learn from data and improve their performance over time without being explicitly programmed. In other words, instead of a human writing a rigid step-by-step program, the machine gains experience from examples and uses statistical algorithms to adjust its own rules. As it processes more data, a machine learning system “learns” and becomes more accurate at its task, much like a human improving a skill through practice.
To understand where ML fits in the AI universe, think of AI as the broad concept of machines carrying out tasks in a “smart” way, and ML as a specific approach within AI. ML (and its offshoot, deep learning) can be visualized as concentric subsets inside the larger AI circle. AI is the parent field encompassing all techniques that enable computers to mimic intelligence. Within AI, Machine Learning algorithms give AI systems the ability to learn and adapt, and within ML, techniques like deep learning (which uses multi-layered neural networks) are specialized methods for achieving that learning. This hierarchy means every deep learning method is a type of machine learning, and every machine learning method is a form of AI.
A classic formal definition of ML, provided by Tom Mitchell, is: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”. In simpler terms, if you can specify the task (such as recognizing images or predicting prices), provide data as experience, and measure how well the computer is doing, an ML system will try to improve that performance by learning from the data.
Key idea: Instead of explicitly programming every rule, we provide data and let the ML model infer the patterns. For example, rather than programming a million rules to identify spam emails, we can feed a machine learning algorithm lots of example emails labeled “spam” or “not spam”. The algorithm will learn the characteristics of spam emails (certain keywords, sender patterns, etc.) and build a model that can classify future emails appropriately. Over time and with more data, the model’s accuracy in filtering spam typically improves, illustrating the “learning from experience” aspect of ML.
In summary, Machine Learning is the engine that allows AI to get smarter with experience. It stands in contrast to traditional programming: instead of developers anticipating every scenario, ML systems derive rules from data. This paradigm has unlocked computer capabilities that were impractical to code manually, such as speech recognition, image understanding, and complex decision-making. Next, let’s journey through the history of how ML came to be such a pivotal part of AI.
A Brief History of Machine Learning
Machine Learning may be a buzzword today, but its conceptual roots stretch back decades. Understanding the historical background and key milestones of ML will give us a perspective on how we arrived at current technologies. Here are some of the pivotal moments in the evolution of ML:
- 1940s – 1950s: Early Concepts and Terminology: The seeds of ML were planted in the mid-20th century alongside the dawn of computer science. Early theorists like Donald Hebb (1949) proposed models for how neurons learn, laying the groundwork for neural networks. In 1950, Alan Turing raised the question “Can machines think?” and introduced the Turing Test, stimulating interest in machine intelligence. By 1956, the field of “Artificial Intelligence” was formally born at the Dartmouth workshop. Just a few years later, in 1959, Arthur Samuel – an IBM researcher – coined the term “machine learning.” Samuel had created a checkers-playing program that improved as it played more games, a groundbreaking example of a computer learning from experience. He famously described ML as the field of study that gives computers the “ability to learn without being explicitly programmed,” capturing the essence of the new approach.
- 1957 – 1960s: The Perceptron and Early Models: In 1957, Frank Rosenblatt introduced the perceptron, an algorithm inspired by neurons that could learn to classify inputs into two categories. This was an early form of a neural network (with a single layer), and it demonstrated that a machine could be “trained” to recognize patterns (for example, classifying simple images). The perceptron was hailed as a breakthrough, and the U.S. Navy invested in it, envisioning machines that could perceive and learn. However, expectations soon met reality – by the late 1960s, researchers (notably Marvin Minsky and Seymour Papert) discovered the perceptron’s limitations in solving more complex problems. This led to a period of reduced funding and enthusiasm (sometimes called an “AI winter”), especially for neural network research. Nonetheless, other strands of AI and ML continued. In the 1960s, researchers developed some of the first reinforcement learning frameworks and simple game-playing programs. For instance, a machine called Cybertron at Raytheon learned to recognize patterns in sonar and ECG signals via trial and error (an early RL approach). By the end of the 1960s, the dream of general AI had tempered, but core ML ideas – learning from data, neural networks, and trial-and-error learning – had been established.
- 1970s – 1980s: New Algorithms and a Resurgence of ML: The 1970s saw ML research broaden into areas like pattern recognition and expert systems. While much AI focus was on manually encoding knowledge (expert systems), some researchers kept pursuing data-driven learning. Decision tree algorithms for classification emerged (the ID3 algorithm was developed by J. Ross Quinlan in 1986), allowing machines to split data based on features and learn simple rule-based classifiers. The late 1970s and 1980s also brought a resurgence in neural network research, thanks in part to the rediscovery of the backpropagation algorithm (1986) for training multi-layer neural networks. Backpropagation allowed “hidden layers” in neural nets to be trained effectively, overcoming the perceptron’s limitations and kickstarting the “connectionist” revival in AI. Around the same time, reinforcement learning was formalized by researchers like Barto, Sutton, and Watkins, establishing methods for an agent to learn via rewards (the Q-learning algorithm was introduced in 1989). In short, the 1980s laid a richer theoretical foundation for ML: new algorithms (decision trees, neural network training, reinforcement learning) and a better understanding of how machines can learn complex patterns. However, computing power was still a limiting factor for very large models.
- 1990s: Statistical Learning and Real-World Achievements: The 1990s saw Machine Learning mature with the influence of statistics. Support Vector Machines (SVMs), introduced in the early 1990s, became a powerful technique for classification tasks, leveraging mathematical optimization to find the optimal decision boundaries. Ensemble methods also rose, with algorithms like Random Forests (1995) combining many decision trees to improve accuracy. ML started delivering notable real-world successes. A famous milestone was IBM’s Deep Blue supercomputer defeating world chess champion Garry Kasparov in 1997 – the first time a machine beat a reigning chess champion under standard rules. While Deep Blue relied more on brute-force search and expert-crafted evaluation functions than learning, it demonstrated the heights AI-assisted systems could reach, marking an inflection point in public awareness of AI. Meanwhile, in the late 90s, speech recognition and handwriting recognition systems using ML (like Hidden Markov Models and neural nets) were deployed in commercial applications. The term “data mining” also became popular, reflecting the growing practice of discovering patterns in large datasets – essentially what we now include under the umbrella of ML. By 1997, another breakthrough in ML algorithms occurred with the invention of LSTM (Long Short-Term Memory) networks, a type of recurrent neural network by Hochreiter and Schmidhuber, which would later be crucial for sequence data (though its impact was felt in the following decades). The 90s closed with Machine Learning transitioning from a niche academic field to a critical tool in many industries, thanks to increasing data and better algorithms.
- 2000s: Big Data and the Rise of Data Science: The early 21st century brought an explosion of digital data (the web, digitization of business records, sensors) and faster computers, which greatly benefited ML. The term “Big Data” became common, and ML algorithms were the natural choice to make sense of these massive datasets. In 2006, Netflix announced the Netflix Prize, a public machine learning competition to improve its movie recommendation algorithm, which drove innovation in collaborative filtering algorithms. Around the same time, Geoffrey Hinton and colleagues popularized the term “deep learning” (2006) to describe new techniques for training multi-layer neural networks. One catalyst for deep learning was the creation of ImageNet, a massive labeled image dataset spearheaded by Fei-Fei Li (introduced in 2009). ImageNet spurred an annual computer vision competition, challenging ML models to recognize objects in 1.2 million images – a scale far beyond earlier datasets. Throughout the 2000s, ML quietly became the backbone of many consumer applications: email spam filters, product recommendation engines, search engine result rankings, stock trading models, and more. Yet, the most dramatic leap was just around the corner, with deep learning poised to take center stage.
- 2010s: The Deep Learning Revolution: The 2010s will be remembered as the decade ML (especially deep learning) achieved breakthrough after breakthrough. A watershed moment came in 2012, when a team led by Hinton won the ImageNet Challenge with a large deep neural network nicknamed “AlexNet.” This convolutional neural network (CNN) dramatically outperformed all previous approaches in image recognition, stunning the computer vision community and triggering an explosion of deep learning research and implementation. Suddenly, deep learning proved its superiority on tasks like image classification, and soon after on speech recognition (around 2012–2013, teams from Microsoft and Google showed deep neural nets halved error rates in speech-to-text). Tech giants and startups alike doubled down on ML investment. Key milestones piled up: In 2014, Generative Adversarial Networks (GANs) were invented, enabling AI to generate startlingly realistic images and data by pitting two neural nets against each other. In 2015, reinforcement learning combined with deep nets led to AlphaGo (Google DeepMind’s system), which in 2016 defeated a world champion Go player – a feat previously thought to be at least a decade away. AlphaGo’s victory (4-1 against Lee Sedol) was heralded as a major breakthrough for AI (Google’s AlphaGo AI defeats human in first game of Go contest), since Go’s complexity had made it a “holy grail” challenge. Meanwhile, transformer networks were introduced in 2017 (“Attention is All You Need” paper), revolutionizing natural language processing (NLP). Transformers enabled models like BERT and later GPT to learn language with unprecedented nuance, leading to AI that can translate, answer questions, and even hold conversations. By the late 2010s, ML and deep learning had firmly entered the mainstream: facial recognition became commonplace, virtual assistants like Siri/Alexa became household tools, and self-driving car prototypes logged millions of miles using ML-based vision and control systems.
- 2020s: The Era of Generative AI and Ubiquitous ML: In the early 2020s, ML is continuing its rapid advance. A notable trend is the rise of generative AI models that create content. OpenAI’s GPT-3 (2020) and GPT-4 (2023) demonstrated that extremely large neural networks trained on vast text data can produce human-like language, write code, and answer complex questions. These large language models and other generative models (like DALL-E 2 and Stable Diffusion for images) burst into public awareness, powering applications like ChatGPT that millions of people now use. This has truly shown how far ML has come, enabling creative and conversational abilities once in the realm of science fiction. Importantly, ML is now ubiquitous: most smartphones perform on-device ML for things like face unlock or predictive text; cloud services offer easy ML tools; and “AI features” are a selling point for many products. AutoML systems (which we’ll discuss later) are automating the design of ML models, making the technology more accessible. According to industry surveys, about half of all organizations had adopted AI in some form by 2022, and the number is climbing. ML is being deployed in healthcare, finance, manufacturing, education – virtually every sector. As of the mid-2020s, we’re also seeing increased focus on ethical AI, ensuring that this powerful technology is used fairly and responsibly (more on that in a later section).
From a single-layer perceptron in the 50s to billion-parameter deep networks today, the journey of Machine Learning has been remarkable. Each milestone – be it a new algorithm or a public triumph like Deep Blue, Watson, or AlphaGo – expanded the realm of the possible. With this historical context in mind, let’s delve into the fundamentals: the different types of machine learning and how these ML algorithms work under the hood.
Types of Machine Learning
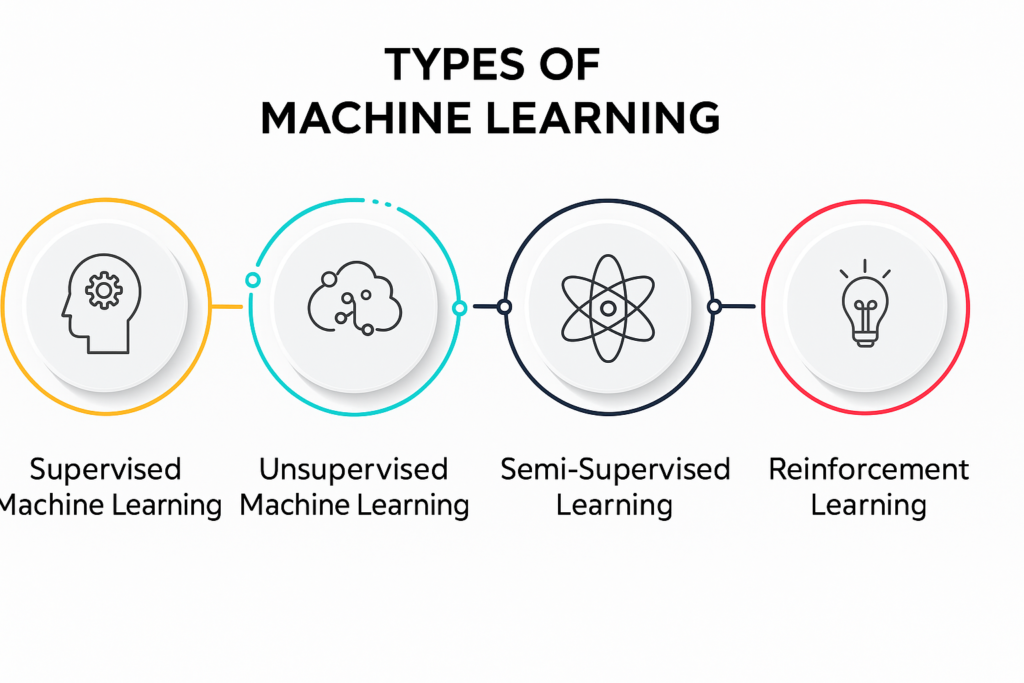
Not all Machine Learning works the same way. ML algorithms are often categorized by the way they learn and generalize from data. The three main types are supervised learning, unsupervised learning, and reinforcement learning (and there are hybrids and subcategories like semi-supervised learning, but we’ll focus on the big three). Each type of ML is suited to different kinds of problems:
- Supervised Learning: This is the most commonly used ML approach. In supervised learning, the algorithm learns from labeled examples, which means each training example comes with an answer key. It’s like learning with a teacher: we provide the model with input data (features) and the correct output (label) for each example, and the model tries to generalize the relationship. For instance, if we want to build an email spam filter, we’ll train a supervised learning model on a dataset of emails (inputs) where each email is labeled “spam” or “not spam” (outputs). Using this, the algorithm can learn patterns that distinguish spam from non-spam. Later, when given a new email, it predicts the label based on its training. Classification and regression are the two main tasks under supervised learning. Classification deals with predicting categories (e.g., spam vs not spam, tumor malignant vs benign), whereas regression predicts continuous values (e.g., predicting house prices from features like size and location). Popular ML algorithms in this category include Linear Regression, Logistic Regression, Decision Trees, Random Forests, Support Vector Machines, and Neural Networks. Supervised learning powers many everyday applications, from product recommendation engines (predicting what you might like) to credit scoring models in finance. It requires good labeled data, which can sometimes be a limiting factor. When abundant labeled data is available, supervised learning can achieve high accuracy – for example, vision models can now recognize thousands of object types in images with superhuman accuracy, given large labeled datasets.
- Unsupervised Learning: In unsupervised learning, we don’t provide explicit labels or correct answers to the algorithm. Instead, the algorithm tries to make sense of the data by finding patterns, structures, or groupings on its own. It’s akin to exploring data without a teacher – the computer must discover interesting relationships without being told what to look for. A classic task for unsupervised learning is clustering: e.g., segmenting customers into groups based on purchasing behavior, without prior labels for what those groups are. The algorithm (like K-means clustering) might reveal natural clusters (say, “bargain shoppers” vs “brand-loyal shoppers” vs “high-spending shoppers”) which a business can then target differently. Another unsupervised task is dimensionality reduction, where the algorithm finds simpler representations of data, for instance, compressing high-dimensional data like images into a few key features (this is how principal component analysis (PCA) works, or how autoencoder neural networks can learn to encode and decode data). Unsupervised learning is often used for exploratory data analysis, anomaly detection (flagging unusual data points that don’t fit any pattern), or generating new data patterns. For example, in cybersecurity, unsupervised models can identify a device’s network behavior that looks very different from its past behavior, flagging a potential breach. A concrete application: market basket analysis in retail uses unsupervised learning to find associations (e.g., customers who buy X also often buy Y). Unlike supervised learning, there is no single objective metric like “accuracy” here, because we didn’t define a correct answer – success is judged by how useful the discovered patterns are. Unsupervised learning is powerful for unlocking insights in unlabeled data, which is abundant in the real world. As one intuitive analogy, unsupervised learning is like discovering the hidden structure of a puzzle without seeing the box cover – the algorithm pieces together what it can on its own. Common algorithms include clustering methods (K-means, hierarchical clustering, DBSCAN), association rule learning (Apriori algorithm for finding frequent itemsets), and various neural network-based approaches for generative modeling.
- Reinforcement Learning (RL): Reinforcement learning is a goal-oriented learning approach, inspired by how animals learn through rewards and punishments. In RL, an “agent” learns by interacting with an environment, making decisions, and receiving feedback in the form of rewards or penalties. There is no fixed dataset with right or wrong outputs; instead, the agent explores and tries actions, and the learning algorithm adjusts the agent’s strategy to maximize cumulative reward. A classic example is a game: consider teaching an AI to play chess or a video game. The RL agent will play many games (its “experience”), and it might only get a positive reward when it wins and negative rewards for losing (or intermediate rewards for good moves). Over time, it will learn what strategies and moves lead to winning more often. This trial-and-error process can be very powerful, albeit computationally intensive. AlphaGo, which we mentioned earlier, is a prime example – it used reinforcement learning (and deep neural networks) to learn Go by playing against itself millions of times. RL is also used in robotics (e.g. a robot learning to walk by rewarding forward motion without falling), operations research (like optimizing trading strategies or scheduling tasks where each action has a long-term payoff), and even autonomous driving modules (where the car AI learns how to make decisions like merging lanes safely by maximizing a reward for progress and safety). The challenge in RL is that feedback can be sparse or delayed – the agent might make many moves before getting a reward, so attributing which action was good can be tricky. Nevertheless, algorithms like Q-learning, Deep Q Networks (DQNs), Policy Gradients, and others have shown that RL can achieve superhuman performance in games and control tasks. It’s an exciting area that blurs the line between AI and robotics/control systems, teaching machines through experience and experimentation.
(There is also semi-supervised learning, which, as the name suggests, mixes a small amount of labeled data with a large amount of unlabeled data. This is useful when labeling data is expensive, and it can give better results than either supervised or unsupervised learning alone in such cases. Another notable approach is self-supervised learning, where the system creates its pseudo-labels from data, for example, predicting the next word in a sentence, and has been key to training large language models. These are advanced variants, but the three categories above cover the core paradigms.)
In practice, choosing between supervised, unsupervised, or reinforcement learning depends on the problem and data at hand. If we have labeled examples of the outcome we care about (like past fraud transactions vs legitimate ones), supervised learning is typically the go-to solution. If we just have a bunch of data and want to find hidden patterns (like grouping customers or compressing data), unsupervised methods are appropriate. And if we’re dealing with an interactive problem where an agent can learn by trial and error (like an AI playing a game or managing an investment portfolio), reinforcement learning is the natural fit.
Understanding these categories helps clarify the strategy an ML project might use. Next, let’s explore some technical foundations: what kinds of algorithms and processes are used to train a machine learning model, how we prepare data for ML, and how we evaluate a model’s performance.
How Machine Learning Works: Algorithms, Training, and Evaluation
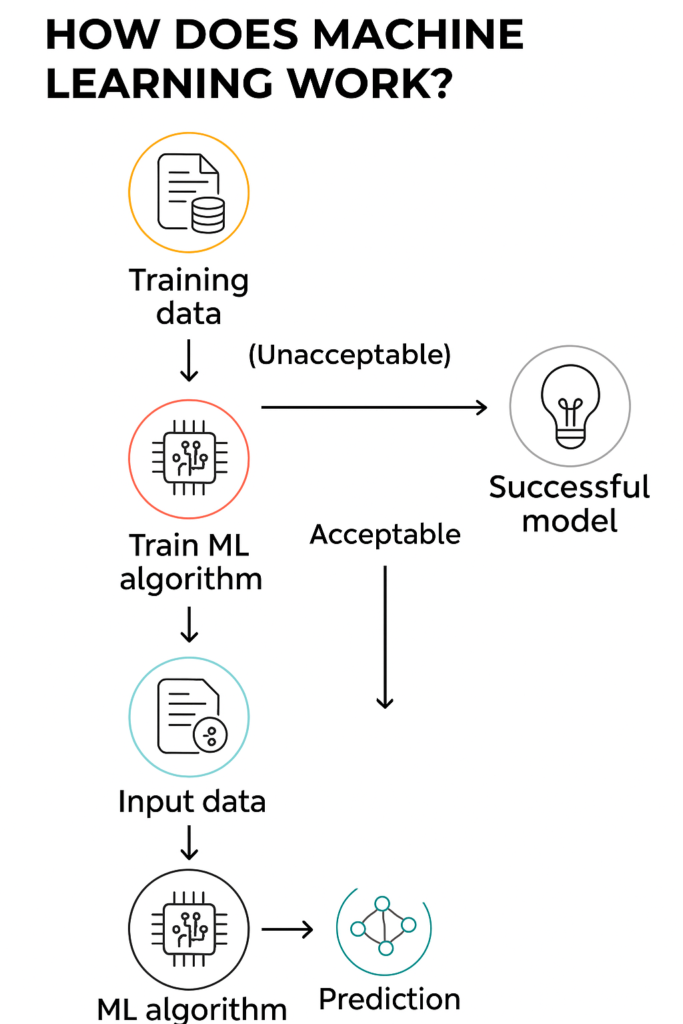
Now that we know the types of ML, let’s dive into the technical backbone of Machine Learning. This section covers the lifecycle of an ML project – from raw data to a working model – and introduces key concepts like algorithms, model training, data preprocessing, and evaluation metrics. Don’t worry if you’re not a math whiz; we’ll keep it intuitive while still hitting the important points.
Common ML Algorithms and Models
Machine Learning offers a toolbox of algorithms, each suited to different types of data and problems. It’s useful to know some of the popular ML algorithms and models:
- Linear Regression and Logistic Regression: These are fundamental algorithms in supervised learning. Linear regression fits a straight line (or hyperplane in higher dimensions) to predict a numeric value, for example, predicting house prices based on size, location, etc. Logistic regression, despite its name, is used for classification (often binary classification); it estimates the probability of an input belonging to a class (e.g. probability that an email is spam) using a logistic function. These models are relatively simple and easy to interpret. They assume a linear relationship between input features and the output, which isn’t always true, but they can be very effective for well-behaved data.
- Decision Trees and Ensembles (Random Forests, Gradient Boosting): Decision trees learn a flowchart-like structure that splits data based on feature values to reach a prediction. For example, a decision tree for loan approval might first check “Income > X?” then “Credit Score > Y?” etc., splitting until it decides “Approve” or “Reject.” They’re easy to interpret, but single trees can be unstable. Ensemble methods improve on this by combining many trees. A Random Forest builds lots of trees with randomness (each tree sees a random subset of features and data) and averages their predictions, reducing variance and improving accuracy. Gradient Boosted Trees (like XGBoost, LightGBM) build trees sequentially, each new tree correcting errors of the previous ones – this often yields extremely accurate models. These ensemble tree methods have been winners in many Kaggle competitions (data science contests) due to their effectiveness on structured data. They handle nonlinear relationships and feature interactions well and work with minimal parameter tuning.
- Support Vector Machines (SVMs): SVMs are powerful classifiers that work by finding the optimal boundary (hyperplane) that separates classes of data with the largest margin. They can use kernel functions to handle non-linear separation by implicitly mapping data to higher dimensions. SVMs were very popular, especially in the 1990s-2000s, for tasks like text classification and image recognition (before deep learning took over those tasks). They can achieve high performance on medium-sized datasets and have a solid theoretical foundation.
- Neural Networks and Deep Learning Models: These are the workhorses of modern ML, especially for unstructured data like images, audio, and text. Inspired by the brain’s neuron connections, artificial neural networks consist of layers of interconnected “neurons” (or nodes) that transform the input data through weighted connections. A basic neural network (or “multilayer perceptron”) might have an input layer, some hidden layers, and an output layer, and can learn very complex functions. Deep learning refers to neural networks with many layers (hence “deep”). Different architectures specialize for different data: for image data, Convolutional Neural Networks (CNNs) excel by using convolutional layers that capture spatial patterns (like edges, textures, shapes in images); for sequence data (like time series or natural language), Recurrent Neural Networks (RNNs) or more modern Transformers capture temporal dependencies (e.g. the context in a sentence). Training deep networks often requires a lot of data and computational power (GPUs), but their performance can be astounding. For instance, deep networks are behind speech recognition systems (transcribing voice to text), machine translation (e.g., English to French), and even the content recommendations on social media. A neural network learns by adjusting weights through a process called backpropagation combined with an optimization method (like gradient descent). Deep models can approximate extremely complex mappings – some are so powerful that they can overfit, essentially memorizing the training data if not regularized. This is why techniques like dropout, regularization, and careful validation are used to keep them from generalizing poorly.
- Bayesian Models: Another category includes models based on Bayes’ theorem and probability. For example, Naive Bayes classifiers are simple yet surprisingly effective for text classification (like spam filtering) – they calculate the probability of a message being spam given the words in it, using the assumption that words contribute independently (hence “naive”). Bayesian approaches provide a probabilistic framework and can incorporate prior knowledge. While not as hyped as deep learning, they remain valuable in certain domains and for understanding uncertainty in predictions.
- Clustering and Dimensionality Reduction Algorithms: On the unsupervised side, algorithms like K-Means clustering attempt to partition data into K clusters by iteratively assigning points to cluster centroids. Hierarchical clustering builds a tree of clusters, which can be cut at a chosen level for a desired number of groups. For reducing dimensionality, Principal Component Analysis (PCA) finds a smaller set of synthetic features that explain most of the variance in the data, useful for visualization or preprocessing. t-SNE and UMAP are newer methods to visualize high-dimensional data in 2D or 3D (like plotting clusters of images or documents) by preserving local structure. These techniques help in understanding data structure and are often an initial step in analysis.
In practice, ML engineers often try multiple algorithms to see which yields the best results for their problem. Simpler models like linear or logistic regression might do surprisingly well on linearly separable data and have the bonus of interpretability (you can see the weight each feature has). More complex models like ensembles or deep nets might win on raw accuracy, especially for complex patterns, but could be harder to interpret and require more data. This is where the “no free lunch” theorem in ML comes in: there isn’t one model that is best for all problems – it depends on the data.
Data Preprocessing and Feature Engineering
The saying “Garbage in, garbage out” is very true in Machine Learning. Data preprocessing is the crucial step of cleaning and preparing raw data to make it suitable for an ML model. In fact, data scientists often spend a large majority of their time on this stage. Key aspects of data preparation include:
- Cleaning the Data: Real-world data is often messy. It may have missing values (e.g., a sensor didn’t record a reading, or a survey question was left blank), which need handling – options include removing those records or imputing a reasonable value (like mean or median for numeric data, or a special “unknown” category for categorical data). There may be outliers (e.g., a typo that a person’s age is 999), which can skew training; we might want to cap or remove extreme values. We also often need to remove duplicates and correct inconsistencies (for example, unify “N/A”, “na”, and empty strings as a single representation of missing). If the data comes from multiple sources, merging and reconciling differences is another task.
- Feature Engineering: These are the transformations or new creations of input variables (features) to better represent the underlying problem to the model. For numeric features, this might mean scaling or normalizing (many algorithms work better when features are on similar scales; e.g., one feature in the range [0,1] and another in [0, 1,000,000] could cause issues – scaling to e.g,. Mean 0 and standard deviation 1 are common. For categorical features (like “City” or “Product Type”), since most ML models expect numbers, we convert categories to numeric encoding – a simple way is one-hot encoding, creating binary columns for each category (e.g. a “City = New York” column that is 1 if true, 0 otherwise, etc.). Text data might require turning words into features – approaches range from simple (like bag-of-words counts or TF-IDF scores for each word) to sophisticated (like word embeddings that deep learning models use). Dates can be engineered into features like “day of week”, “month”, etc., if those are relevant. The process of feature engineering often incorporates domain knowledge – for instance, if predicting whether a credit card transaction is fraudulent, a domain expert might suggest a feature like “distance from home address where the card is used” or “transaction amount compared to the customer’s average”. A well-chosen feature can greatly simplify the learning task. Conversely, irrelevant or redundant features can add noise; part of feature engineering is also feature selection – deciding which attributes to include. Techniques like correlation analysis or even automated methods (like recursive feature elimination) can help choose a good subset of features.
- Splitting Data: Before training any models, we usually split our dataset into at least two parts: a training set and a test set. The training set is what the model learns from, and the test set is held aside to evaluate how well the trained model generalizes to new, unseen data. Often, a further split of a validation set is used (yielding a three-way split: train/val/test) – the model is trained on the train set, tuned on the validation (for hyperparameter tuning or model selection), and final evaluation is on the test set. This prevents “peeking” at the test data during development. A common ratio is 70/15/15 or 60/20/20 (train/val/test), but it can vary. For small datasets, techniques like cross-validation are used: the data is split into k folds, and the model is trained k times, each time using a different fold as the test set and the rest as training, then averaging results. This helps make the most of limited data and get a more stable estimate of performance.
In summary, the data preprocessing step is vital. A well-prepared dataset can make a simple model shine, whereas a poorly prepared dataset will trip up even the most sophisticated algorithm. As Andrew Ng (a leader in ML) often emphasizes, “Coming up with features is difficult, time-consuming, and requires expert knowledge. ‘Applied machine learning’ is feature engineering.” This underscores that domain insight and careful data work often determine success more than fancy algorithms.
Model Training
Once the data is ready and we’ve selected an algorithm, it’s time to train the model. Training means letting the model “fit” the data by adjusting its internal parameters. Here’s a high-level view of training for a supervised learning model:
- Initialize the Model: Depending on the algorithm, this could mean setting initial weights (for neural networks, weights are randomly initialized) or other parameters.
- Feed Training Data: The training algorithm presents the model with the training examples. Often this is done in batches (for efficiency).
- Compute Predictions: For each example (or batch), the model produces a predicted output based on its current parameters.
- Calculate Loss (Error): A loss function or error function measures how far off the predictions are from the true labels. For example, a common loss for regression is Mean Squared Error (the square of differences between predicted and actual values). For classification, a common loss is cross-entropy, which penalizes probability estimates that are far from the actual label.
- Optimize Parameters: The training algorithm then adjusts the model’s parameters to reduce the loss. Many models use gradient descent or its variants – this involves computing the gradient of the loss concerning each parameter (i.e., how should this weight change to reduce error) and nudging parameters in the opposite direction of the gradient. In neural networks, this step is where backpropagation comes in: it efficiently computes gradients for all weights by propagating the error backward through the network. Other algorithms might have closed-form solutions (e.g., the ordinary least squares solution for linear regression can be solved directly without iterative updates) or use optimization techniques like quadratic programming (for SVMs).
- Repeat: This process iterates, often for many epochs (an epoch means one pass through the entire training dataset). Each epoch, the model hopefully gets a bit better. We monitor the training loss, and ideally also check performance on the validation set to ensure it’s improving there too (not just memorizing the training data).
- Stopping Criterion: We stop training when either we’ve done a fixed number of epochs or when improvement stalls (or when performance on validation starts degrading, indicating overfitting). Early stopping is a regularization technique where we stop when the validation error starts to rise, to avoid overfitting.
During training, there are also hyperparameters to consider – these are settings not learned by the model but set by us. Examples include the learning rate in gradient descent (how big of a step to take when adjusting weights), the depth of a decision tree, the number of neurons in a neural network layer, etc. These are often tuned through experiments, trying different values and seeing which yields the best validation performance. This is where approaches like grid search or random search come in, and also where AutoML (which we’ll cover later) aims to automate the process.
A concept to be mindful of is overfitting vs. underfitting:
- Underfitting occurs when the model is too simple to capture the underlying pattern of the data – it performs poorly on training data and thus also on new data. (Imagine fitting a straight line to data that is quadratic – it just can’t catch the curve.)
- Overfitting happens when the model is too complex and starts memorizing quirks or noise in the training data rather than the true pattern – it might do exceptionally well on training data but then fail to generalize to test data. (Imagine a decision tree that has grown so deep it perfectly classifies the training points, but essentially each leaf is just one sample – it hasn’t learned a general rule.)
The goal is a just-right model complexity that captures the signal but not the noise. Techniques to combat overfitting include regularization (adding a penalty in the loss for complexity, such as L1 or L2 regularization that penalize large weights), pruning decision trees, dropout in neural nets (randomly dropping units during training to prevent co-adaptation), and of course having more training data if possible.
Evaluation Metrics
After training a model, we need to evaluate how well it performs, especially on data it hasn’t seen (our test set), because we care about real-world performance, not just memorizing the training set. Different tasks use different evaluation metrics. Here are some of the most common ones:
- Accuracy: Simply the fraction of predictions the model got right. This is used for classification tasks. For example, if out of 100 test emails, the model correctly identifies 90 as spam/ham, the accuracy is 90%. Accuracy is easy to understand, but can be misleading if the classes are imbalanced. Consider a dataset of 99% non-spam and 1% spam; a model that always predicts “not spam” will be 99% accurate, but is obviously useless for detecting spam. So, for imbalanced data, we look at other metrics.
- Precision, Recall, F1-Score: These are used for classification (especially binary classification) to get a fuller picture than accuracy. Precision is the proportion of positive predictions that were actually correct (e.g., of all emails the model flagged as “spam”, what % were truly spam). Recall (or sensitivity) is the proportion of actual positives the model correctly identified (e.g., of all spam emails in the set, what % did the model catch). There is often a trade-off between precision and recall (e.g, a model could mark almost everything as spam to catch all spam – high recall, but then many legitimate emails get caught – low precision). The F1-score is the harmonic mean of precision and recall, providing a single metric that balances the two. It’s useful when a positive class is rare and we want to balance false positives vs false negatives.
- Confusion Matrix: Instead of a single metric, a confusion matrix gives a breakdown of predictions vs actual values (true positives, false positives, true negatives, false negatives). It’s very useful for diagnosing what kinds of errors a classifier makes. From it, we derive precision/recall and other measures.
- ROC AUC (Receiver Operating Characteristic – Area Under Curve): For binary classification, especially if we want to consider different thresholds, ROC AUC is a popular metric. It measures the trade-off between true positive rate and false positive rate across all possible thresholds. An AUC of 1.0 is perfect, 0.5 is random guessing. This is useful if we care about ranking predictions or the overall separability of classes rather than a specific threshold.
- Mean Squared Error (MSE) / Mean Absolute Error (MAE) / R²: For regression tasks (predicting continuous values), common metrics include MSE (average of squared differences between predicted and actual values), RMSE (root of MSE, in the same units as the target), and MAE (average of absolute differences). MSE penalizes large errors more due to squaring, while MAE gives a more direct average error. There’s also R² (R-squared), the coefficient of determination, which indicates the proportion of variance in the target that is explained by the model – an R² of 1 means perfect fit, 0 means the model is no better than predicting the mean, and it can be negative if the model is worse than that.
- Log Loss / Cross-Entropy: For probabilistic classifiers, log loss measures how well the predicted probability distribution matches the actual outcomes. It heavily penalizes confident wrong predictions. Many ML challenges (like Kaggle competitions) use log loss for evaluation when the output is a probability.
- Others: There are many domain-specific metrics, too. For ranking problems (like search engine results), metrics like NDCG (Normalized Discounted Cumulative Gain) are used. For clustering, metrics like the silhouette score or adjusted rand index can evaluate how good the clustering is (though clustering evaluation often requires a “ground truth” which may not exist). In image segmentation (where each pixel is classified), Intersection-over-Union (IoU) is used. The choice of metric should correspond to what success means for the problem at hand.
When we evaluate on the test set, this ideally simulates how the model would perform on new data in production. If the model performs well on training but much worse on test, it’s overfitting. If it performs poorly on both, it’s underfitting or just not suitable. This evaluation guides us on whether we need to go back and try a different model, get more data, do more feature engineering, etc.
It’s also a good practice to perform cross-validation during training to ensure the model’s performance is consistent and not a fluke on one particular split of data. This helps in model selection (choosing which algorithm or which hyperparameters yield the best generalization performance).
Example – Putting it Together:
To make these ideas more concrete, imagine we are building an ML model to predict whether a patient has a certain disease from diagnostic measurements (a classic binary classification):
- Data preprocessing: We collect a dataset of patients with their test results (blood pressure, cholesterol, etc.) as features and whether they had the disease as the label. We clean it (e.g., fill in a few missing cholesterol values with the median, remove an obvious outlier where the age was recorded as 300). We then normalize the numeric features so that, say, blood pressure and cholesterol values are on comparable scales. We might create a new feature, like Body Mass Index (BMI) from weight and height, if that’s relevant medically. We split the data: 80% train, 20% test (and perhaps further split part of the train into validation).
- Model choice and training: We decide to try a few models – say, a logistic regression, a decision tree, and a random forest. Using our training set, we train each. For the logistic regression, we might need to choose a regularization strength; for the tree, we might limit its depth; for the random forest, we decide the number of trees. We use 5-fold cross-validation on the training set to tune these hyperparameters. Suppose we find the random forest with 100 trees gives the best validation performance.
- Evaluation: We then evaluate the chosen model on the held-out test set. We get, for example, 88% accuracy. But since the disease is somewhat rare in the population (say 10% prevalence), we also look at recall – perhaps it’s catching 80% of true cases – and precision – perhaps 50% of those it flags as positive are actual positives. Depending on the context (maybe missing a disease case is very costly, so we care more about recall), we interpret the results. We might also look at the ROC curve; if the AUC is e.g. 0.93, that’s a strong indicator that the model has good discrimination ability. We examine the confusion matrix: maybe it misclassifies some positive cases as negative. We analyze those cases to see if there’s a pattern (e.g., perhaps young patients’ cases are often missed – that could lead us to add age as a more prominent feature or collect more data on younger patients).
- Iterate: If performance is not satisfactory, we might go back and try more feature engineering (maybe a medical expert suggests a ratio of two lab results is important), or try a more complex model, etc. This iterative process continues until we have a model that meets our success criteria.
By following this process – preparing data well, choosing an appropriate algorithm, carefully training and tuning it, and evaluating with the right metrics – we increase the chance that our ML model will perform well when deployed.
Having covered the foundational process of ML, let’s shift gears and see how these models are being used. In the next section, we’ll explore real-world applications of Machine Learning across various industries, from healthcare to finance to marketing and beyond.
Applications of Machine Learning in the Real World
Machine Learning isn’t just a theoretical exercise; it’s driving innovations and efficiencies in virtually every industry. Let’s explore how ML is applied in healthcare, finance, marketing, manufacturing, and more, highlighting concrete examples in each domain. This will illustrate the breadth of ML’s impact – and perhaps spark ideas for new applications.
- Healthcare and Medicine: Machine Learning is revolutionizing healthcare in areas ranging from diagnostics to personalized medicine. In medical imaging, ML models (especially deep learning CNNs) are now able to analyze X-rays, MRIs, and CT scans to detect diseases like cancers, often with accuracy comparable to expert radiologists. For example, ML systems can flag early signs of tumors or diabetic retinopathy in eye scans, enabling earlier intervention. Predictive analytics in healthcare uses ML to predict patient outcomes, such as which patients are at high risk of complications or readmission, allowing preventive care. ML also accelerates drug discovery: algorithms sift through large chemical datasets to identify potential drug candidates or to predict how a given molecule will behave. In genomics, ML helps in analyzing DNA sequences to find gene-disease associations. Electronic health records (EHR) analysis is another big area: natural language processing (NLP) models can read doctors’ notes to identify trends or to assist in clinical decision support. During the COVID-19 pandemic, ML models were used to forecast outbreak trends and to assist in vaccine and treatment research. Overall, healthcare has been an early adopter of ML technologies and continues to benefit from them. A notable example is IBM’s Watson for Oncology (though it had mixed success), which attempted to recommend cancer treatments by learning from medical literature. Hospitals are now using ML-driven systems for tasks like optimizing staff schedules, predicting no-show appointments, and even detecting insurance fraud. The promise for the future is personalized medicine, where ML models will tailor treatments to individual patients’ genetic and clinical profiles – a level of customization that could greatly improve outcomes.
- Finance and Banking: The finance industry was quick to leverage ML for its abundance of data and quantitative nature. Fraud detection is a classic application – credit card companies and banks use ML algorithms to spot anomalous transactions in real-time (for instance, if your card is suddenly used in a faraway city for an unusual purchase, an ML model may flag it as suspicious based on learned patterns of fraud). These models continuously learn from new fraud cases to adapt to the evolving tactics of fraudsters. Algorithmic trading and portfolio management are another arena: hedge funds and trading firms employ ML models (sometimes very sophisticated deep learning models) to analyze market data and execute trades at high speed, looking for patterns or arbitrage opportunities that humans might miss. Risk modeling in banking (credit risk, market risk) often uses ML to assess the likelihood of loan defaults or market movements by learning from historical data. For example, instead of relying solely on a credit score, a bank might feed a rich dataset of customer information into an ML model to decide on loan approval, aiming to be both more inclusive and more accurate in predicting default risk. Customer service in finance has also been enhanced by ML through chatbots and automated support – many banks have virtual assistants that can answer questions like “What’s my account balance?” or help troubleshoot issues, using NLP to understand customer queries. Personal finance management apps use ML to analyze spending habits and provide insights or budgeting advice. Another growing area is AML (Anti-Money Laundering) and compliance – ML models scan through transaction data to detect patterns indicative of money laundering or other illicit activities, which are often complex and multi-step (hence well-suited for pattern recognition algorithms). Overall, ML helps the finance industry by improving security, making data-driven decisions faster, and providing personalized financial services (like robo-advisors that allocate your investments based on your goals and risk tolerance using ML).
- Marketing and Sales: In the era of big data, marketing has become a precision science powered by ML. One of the most visible applications is recommendation systems on e-commerce and content platforms – think of Amazon suggesting products, Netflix recommending movies, or Spotify curating playlists for you. These recommender systems learn from your past behavior and that of similar users (collaborative filtering) as well as item attributes to predict what you might be interested in. They are incredibly valuable for driving engagement and sales. Customer segmentation is another marketing use: unsupervised learning clusters customers into distinct segments based on behavior and demographics, allowing targeted campaigns. ML also powers targeted advertising – models decide which ad to show you when you browse the web or social media, based on your profile and likelihood to click or convert. This real-time bidding and ad targeting is almost entirely machine-driven now, optimizing for engagement or sales. Dynamic pricing is used in retail and travel (e.g., airlines adjusting ticket prices or Uber’s surge pricing) by forecasting demand and willingness to pay. ML helps figure out the optimal price to maximize revenue while staying competitive. Lead scoring in sales uses ML to evaluate which prospects are most likely to become customers, so sales teams can prioritize them. In email marketing, ML can personalize content, for instance, deciding the best time to send an email to each user or customizing product content in the email. Natural language processing models analyze social media and customer feedback for sentiment analysis, so companies can gauge public opinion about their brand or find trending topics. ML-driven chatbots on websites engage users in conversation, guiding them or answering FAQs, which improves customer experience and frees up human reps for complex cases. According to industry reports, these applications of ML in marketing have significantly improved ROI by delivering the right message to the right user at the right time, something that was far more hit-or-miss in traditional marketing. Overall, ML in marketing enables a level of personalization and efficiency that scales to millions of customers, which would be impossible with manual analysis.
- Manufacturing and Industry 4.0: The manufacturing sector is experiencing a transformation often referred to as Industry 4.0, where IoT (Internet of Things) sensors and ML come together to create smarter factories. A prime application is predictive maintenance: instead of servicing machines on a fixed schedule, companies use ML to predict when a machine is likely to fail or need maintenance, based on sensor data (vibration, temperature, sound, etc.). By catching issues early, they can prevent costly downtime. For example, an ML model might learn the normal vibration frequency signature of a motor and alert when it detects patterns that usually precede a failure. This minimizes unexpected breakdowns and optimizes maintenance cycles, saving money. Quality control is another area – computer vision systems on production lines can automatically inspect products for defects (for instance, checking circuit boards for soldering issues or scanning bottles for fill level and cap seal). ML models can often detect subtle anomalies more reliably than a quick human visual check and can do so at high speed. Robotics in manufacturing often uses ML for control and vision, enabling robots to adapt to variability (like picking and placing objects that aren’t in the same position each time by “seeing” them with cameras). Supply chain optimization benefits from ML through better demand forecasting (predicting how much of each product will be needed so that inventory levels can be optimized) and logistics (finding efficient routing and delivery schedules). Companies like Amazon use ML to manage warehouse inventory placement and to decide the most efficient way to fulfill orders (choosing the warehouse and route). Energy management in factories is another aspect – ML can smartly regulate energy usage, predict peak demand times, and reduce waste (this overlaps with smart grid applications in utilities). Process optimization: In complex manufacturing processes (like chemical production or semiconductor fabrication), there are many parameters to tune; ML can model the process and suggest optimal settings to maximize yield and minimize defects, sometimes discovering non-intuitive improvements. In summary, Machine Learning makes manufacturing more efficient, less wasteful, and more adaptive, ushering in smarter factories that can self-monitor and self-optimize.
- Transportation and Automotive: We’ve all heard about self-driving cars – that’s a showcase of ML (particularly deep learning and reinforcement learning) in action. Autonomous vehicles use a suite of sensors (cameras, lidar, radar) and ML models (especially deep neural networks) to perceive the environment (lane detection, pedestrian recognition, traffic sign reading) and make driving decisions. While full autonomy is still being perfected, many cars today have advanced driver-assistance systems (ADAS) powered by ML: features like automatic emergency braking (the car detects an impending collision and brakes), adaptive cruise control, lane-keep assist, and self-parking. Ridesharing companies use ML for dynamic pricing (surge pricing algorithms) and to match drivers to riders efficiently. In logistics and delivery, ML optimizes routes – for example, UPS’s ORION system uses ML and algorithms to plan delivery routes that save millions of miles of driving. Traffic management in smart cities applies ML to sensor and camera data to control traffic light timings and predict congestion, aiming to reduce jams. Public transit systems forecast ridership to allocate resources. Even aviation uses ML for optimizing fuel efficiency and predictive maintenance of aircraft components. Railways use ML to schedule maintenance of tracks by analyzing vibration data from trains. One fun example: some cities are experimenting with ML-driven adaptive traffic signals that adjust in real time to traffic conditions (reducing wait times when possible). In summary, ML is making transportation safer, more efficient, and more adaptive – from how individual vehicles operate to how large fleets and networks are managed.
- Retail and E-commerce: Besides the recommendation systems and dynamic pricing mentioned earlier, retailers use ML for demand forecasting – predicting sales for each store and product to manage inventory better (so shelves are stocked appropriately without overstock). Inventory management itself is optimized with ML to automate reordering and distribution between warehouses. Some stores have implemented computer vision for autonomous checkout (e.g., Amazon Go stores use cameras and ML to let customers grab items and leave, automatically charging them – no checkout line). ML also helps in customer relationship management (CRM) by predicting customer churn (which shoppers are unlikely to return, so the store can target them with retention offers) and estimating customer lifetime value. Recommendation engines on retail sites boost cross-selling (“customers who viewed this also viewed…”). Chatbots handle routine customer queries online, as previously noted. Marketing attribution – figuring out which marketing channel or campaign led to a sale – is aided by ML models that analyze customer journeys. Additionally, fraud detection in retail (especially online transactions) is crucial, similar to finance. For brick-and-mortar retailers, ML can analyze surveillance video to understand store traffic patterns, where customers linger, etc., to optimize store layout (this overlaps with some privacy concerns, but technically it’s feasible). Supply chain aspects like finding the most efficient shipping routes or choosing the source for each order (which warehouse should ship it) are optimized by ML to cut costs and delivery times. All these applications lead to smoother operations and a more personalized shopping experience, which is why retail giants heavily invest in ML.
- Others (“and more”): It’s hard to find an area untouched by ML. In agriculture, ML-driven robots and drones monitor crop health, ML models predict yields, and smart irrigation systems use ML to optimize water usage. Energy sectors use ML to predict equipment failures in power plants, forecast energy supply and demand (crucial with renewable sources that depend on weather), and optimize grid distribution. Entertainment: streaming services like Netflix and Spotify use ML not just for recommendations but also to personalize content thumbnails, optimize compression, and even decide on content production by analyzing viewer preferences. Education: ML powers intelligent tutoring systems that personalize learning material for students, automated grading of assignments, and even helps identify students at risk of falling behind through performance data. In human resources, ML is used for resume screening (though it has raised fairness concerns), employee attrition prediction, and even matching candidates to roles. Security: cybersecurity companies employ ML to detect malware and network intrusions by recognizing patterns of behavior that indicate attacks (since cyber threats constantly evolve, ML helps adapt detection). Environmental science: ML helps in climate modeling, wildlife conservation (e.g., identifying animal species in camera trap photos, spotting illegal deforestation via satellite imagery), and earthquake prediction research by finding subtle patterns in seismic data. Art and creativity: interestingly, ML is enabling new forms of art – algorithms that generate paintings, music, or writing (generative models) open up human-AI collaboration in creative fields.
This list could go on – the key point is that Machine Learning has become a general-purpose technology much like electricity or the internet. It’s adaptable to many contexts, wherever there is data. Indeed, a TechTarget article noted that ML’s “omnipresence impacts the daily business operations of most industries” today. Companies are collecting vast amounts of data, and ML is the tool that unlocks insights and automation from that data, whether the goal is reducing costs, increasing revenue, improving safety, or creating new products and services.
After seeing all these applications, a natural question is: what’s enabling all this progress recently, and what innovations are pushing ML even further? In the next section, we’ll discuss some recent advancements in ML that are expanding its capabilities and making it more accessible.
Recent Advancements in Machine Learning
The field of Machine Learning is continually evolving. In the last few years, there have been significant advancements that have pushed the boundaries of what ML can do and made it easier to develop powerful models. In this section, we’ll highlight a few key trends and innovations: AutoML (Automated Machine Learning), Transfer Learning, and Deep Learning’s latest developments. We’ll also touch on other notable advances like large language models and federated learning as part of the broader context.
- Automated Machine Learning (AutoML): As ML has become more ubiquitous, a major challenge is the time and expertise needed to develop a high-performing model. AutoML aims to automate the end-to-end process of applying machine learning to real-world problems. This includes automating tasks such as selecting the best model/algorithm for the given data, tuning hyperparameters, preprocessing steps, and sometimes even feature engineering. In essence, AutoML tools act as a “data scientist in a box,” trying out many combinations of pipelines and finding one that yields the best results. For example, you could provide an AutoML system with a raw dataset (with labels for supervised learning), and it might automatically try normalization vs. standardization, different sets of features, train a bunch of candidate models (like gradient boosting, neural nets, SVMs, etc.), and give you the top performer without you needing to manually do those experiments. This significantly lowers the barrier to entry – non-experts can get reasonable models without in-depth knowledge of ML algorithms. Even for experts, AutoML can save time on tedious trial-and-error. Major tech companies have incorporated AutoML: Google’s Cloud AutoML, Microsoft’s AutoML in Azure ML, and open-source projects like Auto-sklearn, TPOT, and H2O’s AutoML. AutoML has its limitations (it might not yet do very clever feature engineering that a domain expert could), and truly hands-free automated modeling is an ongoing research area. But it’s a big recent trend that indicates the democratization of machine learning – more people can harness ML’s power without needing a PhD in the field. In the future, we might see AI systems building other AI systems routinely. In fact, neural architecture search, which is a form of AutoML focusing on finding optimal neural network architectures, has already led to designs of neural nets that rival human-designed ones for tasks like image classification. AutoML touches on the notion of AI building AI, which is exciting and a bit meta!
- Transfer Learning: Traditionally, machine learning models are trained from scratch for each task, requiring sufficient data for that specific task. Transfer learning turns this on its head by reusing knowledge from one task to benefit another. The idea is simple: leverage a model that’s already learned useful representations from one domain and fine-tune it on a new domain. This has been a game-changer, especially in deep learning. For example, consider training a deep neural network for image recognition. Instead of training a huge CNN from random initialization on a small dataset of, say, medical images (which could lead to overfitting due to limited data), one common approach is to take a CNN that was pretrained on ImageNet (a massive 1.2M image dataset of everyday objects) and then fine-tune it on the medical images. The lower layers of the CNN, which detect edges and textures, are reusable general knowledge. The higher layers might be adjusted slightly to the specifics of medical images. This often yields much better performance with far less data and compute than training from scratch. Similarly, in NLP, models like BERT and GPT are trained on enormous corpora (like all of Wikipedia, billions of webpages, etc.) to learn the structure of language in a self-supervised way. These pretrained language models can then be fine-tuned on a smaller dataset for a specific task (like sentiment analysis or question answering), dramatically improving results with minimal task-specific data. Transfer learning works because many tasks have overlapping structure – what a model learns in one context (like understanding generic visual shapes or grammar structure) can help in another context. It’s analogous to human learning: knowing how to play the piano can help you learn the organ faster than someone with no musical background, because you transfer your knowledge of reading music and coordination. In ML, transfer learning has become standard practice in computer vision and NLP. It has enabled state-of-the-art results with fewer resources and opened up advanced AI capabilities to those with smaller datasets. As a result, we’re seeing a proliferation of pretrained models being shared (on repositories like TensorFlow Hub or PyTorch Hub) for others to fine-tune – a great example of communal progress. Moreover, multitask learning and few-shot learning (learning from very few examples) are related areas that benefit from similar principles of knowledge reuse. Overall, transfer learning is about leveraging “What’s already learned?” – a powerful shortcut in ML that reflects how we build upon past knowledge.
- Advances in Deep Learning: Deep learning itself, which we covered in the history and algorithms sections, continues to advance at a rapid clip. A few noteworthy recent developments:
- Architectural Innovations: The introduction of the Transformer architecture (Vaswani et al., 2017) has revolutionized NLP and even spread to vision (Vision Transformers). Transformers enable models to pay selective “attention” to different parts of the input and have led to huge breakthroughs in language understanding and generation. Using Transformers, researchers built ever larger models (like the GPT series and BERT) that learned surprisingly general language skills by simply scaling up data and parameters. We’ve also seen architectures like GANs (for generative tasks) mature – GAN-based image generators can now create photorealistic faces that are indistinguishable from real ones. Variational Autoencoders (VAEs) and Normalizing Flows have also provided ways to learn generative models with a probabilistic underpinning.
- Scalability and Foundation Models: There’s a trend toward large-scale models pre-trained on broad data (so-called “foundation models”). GPT-3, for example, has 175 billion parameters and was trained on text from the internet. These models are not trained for one specific task but rather general-purpose – they can be adapted to many tasks (via fine-tuning or even prompting) and have exhibited emergent capabilities (like being able to do arithmetic or code generation) that weren’t explicitly programmed. OpenAI’s GPT-4 (2023) further scaled this concept, becoming multimodal (accepting text and image inputs) and demonstrating reasoning abilities that inch closer to human-like performance in various knowledge tasks. Such models are transforming how we approach AI development: instead of training a model from scratch for each task, one can often leverage a massive pre-trained model and then specialize it. This approach, however, comes with challenges – these models are resource-intensive to train and can be opaque and sometimes behave unexpectedly, raising the need for careful evaluation (more on ethics soon).
- AutoML and Neural Architecture Search: As mentioned, deep learning researchers have started to use algorithms to design better neural network architectures than humans might come up with. For instance, Google’s AutoML project resulted in NASNet, a CNN architecture discovered via neural architecture search that achieved top image classification performance. We’re even seeing hypernetworks or meta-learning networks that learn to configure other networks.
- Improved Training Techniques: New optimization and regularization techniques continue to appear. For example, Adam optimizer became popular in the mid-2010s as an improvement over basic stochastic gradient descent for many problems. Techniques like batch normalization (which stabilizes and accelerates training) are now standard. Researchers also devise clever ways to initialize networks, schedule learning rates (cyclical learning rates, warm restarts), and more, all to make training deep nets more stable and faster.
- Interpretability and Explainability in Deep Learning: There’s a push to understand what deep networks have learned. Techniques like feature visualization can show what patterns neurons respond to (like certain neurons in a vision model might respond to “dog faces” or “wheel shapes”). SHAP values and LIME are methods to explain model predictions locally by approximating the model’s behavior around a specific input. While these aren’t improvements in raw performance, they’re advancements in how we work with deep models and trust them.
- Deep Learning in New Domains: Deep learning is being applied in some less traditional areas like drug molecule design (with graph neural networks modeling molecular structures), protein folding (DeepMind’s AlphaFold used DL to predict 3D protein structures with astonishing accuracy, solving a 50-year science problem), and even mathematics (some research uses DL to conjecture or prove mathematical statements by pattern recognition in data of examples).
- Architectural Innovations: The introduction of the Transformer architecture (Vaswani et al., 2017) has revolutionized NLP and even spread to vision (Vision Transformers). Transformers enable models to pay selective “attention” to different parts of the input and have led to huge breakthroughs in language understanding and generation. Using Transformers, researchers built ever larger models (like the GPT series and BERT) that learned surprisingly general language skills by simply scaling up data and parameters. We’ve also seen architectures like GANs (for generative tasks) mature – GAN-based image generators can now create photorealistic faces that are indistinguishable from real ones. Variational Autoencoders (VAEs) and Normalizing Flows have also provided ways to learn generative models with a probabilistic underpinning.
All these advancements contribute to a landscape where ML models are more powerful, more general, and easier to build than ever before. For instance, something like GPT-3 exemplifies several of these trends: it was built via massive scale deep learning, partially automated architecture (Transformers), on a broad dataset, and it uses transfer learning (in the form of being adapted to tasks via prompts or fine-tuning) to achieve things like writing code or summarizing text. It even involved significant hyperparameter tuning (some automated) to get it right. As a result, GPT-3 and its successors can perform tasks with little to no training data (so-called few-shot learning by providing a few examples in the prompt), which was previously unheard of at such quality.
Another advancement worth noting is Federated Learning – a solution to an emerging problem: how to train on data that is distributed across devices or silos without aggregating it (for privacy). In federated learning, the model is trained cooperatively by multiple devices (like phones) that each have local data; only the model updates (gradients) are sent to a central server to be aggregated, not the raw data. This way, your smartphone can help train a predictive text model by learning from your messages, but your messages never leave your device – only the learned weight updates do. This preserves data privacy while still benefiting from collective learning. It’s an active area of development as privacy becomes a bigger concern in ML.
Speaking of privacy and fairness, as ML becomes more powerful and widespread, it brings ethical challenges to the forefront. We’ve touched on technical achievements; next, we must consider the responsible use of this technology. In the following section, we’ll discuss ethical considerations in Machine Learning, including data privacy, bias/fairness, and explainability, which are crucial aspects of recent conversations around AI.
Ethical Considerations in Machine Learning
With great power comes great responsibility. The rise of Machine Learning has brought along ethical and societal challenges that we must address to ensure ML systems are fair, trustworthy, and safe. Key areas of concern include data privacy, bias and fairness, and explainability (transparency of AI decisions). Let’s explore each of these, along with examples, to understand why they matter and what’s being done.
- Data Privacy: Machine Learning models are hungry for data, often personal data, which raises privacy issues. When companies collect data from users (be it clicks, locations, health records, or voice recordings), there is a duty to handle that data responsibly. Users might not even know how their data is being used to train models. One privacy concern is that ML models can sometimes memorize parts of the training data, especially large models trained on vast text (some language models have unintentionally memorized private information from the internet, like personal names, contact info present in the training set). This can lead to data leaks if not mitigated. Regulations like the EU’s GDPR (General Data Protection Regulation) enforce the idea that individuals have rights over their data, including the right to have it deleted, and that includes data used in automated decision-making. Companies have to ensure compliance, which might involve allowing users to opt out of data collection or deleting their data from training sets on request. Techniques like differential privacy are being developed to train models in a way that individual data points have limited influence on the model (so the model can learn general patterns but provably not store specific personal details). As mentioned earlier, federated learning is another approach that keeps data on user devices and only shares model updates, thus reducing the risk of central data breaches. Privacy is especially crucial in sensitive domains: for example, if a health ML app collects your heart rate and sleep data to give insights, users would expect that information to remain confidential and not be misused or exposed. There have been public concerns like the realization that smart assistants (Alexa, Siri) had human reviewers listening to some recordings to improve ML models – users felt it was a violation since they didn’t realize humans might hear their commands. In response, companies had to adjust policies (e.g., taking explicit consent for voice recordings). In sum, respecting privacy in ML is not only an ethical mandate but also important for maintaining public trust. Solutions include data anonymization (removing personal identifiers), secure data storage, using only data truly needed for the task, and being transparent with users about data usage.
- Fairness and Bias: “Machine Learning models are only as good as the data we feed them,” and if that data reflects historical biases or inequalities, the model can end up perpetuating or even amplifying those biases. This is a major concern for ML systems used in high-stakes areas like hiring, lending, criminal justice, and healthcare. For example, there have been cases where ML models used to screen job applicants were found to be biased against women because the training data (past hiring decisions or resumes) reflected a male-dominated industry. Amazon famously had to scrap an internal recruiting tool because it learned to downgrade resumes that contained indicators of being female (like women’s colleges or certain keywords) – it learned this from historical hiring data, where men were hired more often in those roles. Another example: face recognition algorithms a few years back were far more accurate on white male faces and had high error rates on darker-skinned female faces. One study found error rates below 1% for light-skinned men but as high as 34% for dark-skinned women, meaning women of color were often misidentified. This kind of disparity can lead to serious consequences – in law enforcement, using such a biased face recognition system could wrongfully implicate innocent people. Bias can creep in through unrepresentative training data (if a dataset doesn’t include enough examples of a certain group, the model may not learn well for that group) or through labels that reflect human prejudices (for instance, past loan approval data might reflect societal biases – if a model learns from that, it may score certain minorities as higher risk unjustly). Ensuring fairness in ML means actively checking for these biases and finding ways to mitigate them. Techniques have emerged for fairness-aware machine learning: for example, rebalancing training data, altering algorithms to include fairness constraints (so they don’t disproportionately impact a protected group), or post-processing model outputs to equalize outcomes. Fairness is tricky, though – there are multiple definitions (equal accuracy across groups? equal false positive rates? etc.), and sometimes they conflict, so context matters. The field of Responsible AI often involves fairness audits – testing a model for bias and addressing any issues before deployment. Importantly, fairness isn’t just a technical issue; it requires involving diverse stakeholders and understanding social dynamics. But at its heart, the goal is that ML systems do not discriminate or harm disadvantaged groups, and ideally even help reduce human bias by making more objective decisions. Addressing bias is not only ethically right, it can also be required by law (e.g., in credit lending in the U.S., discriminatory models can violate the Equal Credit Opportunity Act). High-profile examples, as mentioned, have raised awareness: from biased hiring tools to biased criminal risk scoring software (like COMPAS, which was accused of bias against Black defendants). These cases are prompting more rigorous standards.
- Explainability and Transparency: Many ML models, especially complex ones like deep neural networks or ensemble models, operate as “black boxes” – they make predictions, but understanding why they made a certain decision can be difficult. In critical applications, a lack of explainability is a problem. For instance, if an ML model denies someone a loan or a job, the person might want an explanation. Under some regulations (like GDPR’s clauses about automated decision-making), individuals have a right to an explanation of algorithmic decisions. Moreover, from a practical standpoint, organizations need to trust and verify model behavior; a doctor won’t blindly follow an AI’s diagnosis suggestion unless it can highlight the factors that led to that conclusion convincingly. Explainable AI (XAI) is a field focused on making ML’s decisions more interpretable to humans. There are a variety of approaches: some involve using inherently interpretable models (like decision trees or linear models) if possible, or simplifying a complex model into an approximate interpretable one. Others produce local explanations – e.g., LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations), which generate an explanation for an individual prediction by seeing how changing each input feature affects the outcome. For example, a SHAP explanation for a loan application might say: income and credit history were the top positive factors for approval, while a high debt-to-income ratio was a negative factor, leading to the final decision. Having this clarity helps build trust, allows human experts to catch any obvious mistakes or biases, and is often essential for compliance (in finance or healthcare, you often must be able to justify decisions). Another aspect is model transparency – knowing what data went in and how it was processed. This includes datasheets for datasets and model cards (documentation initiatives that describe the intended use, performance, and limitations of models). Imagine a scenario: an AI system denies parole to an inmate based on a risk score. If that person asks “Why?”, an uninterpretable “the neural net’s weights said so” is not acceptable. But if we can say, for instance, “Because the inmate had multiple prior offenses and failed to appear in past hearings, which historically correlates with re-offending,” it provides a rationale that can be evaluated. Of course, with black-box deep learning, extracting such a rationale is challenging, but research (saliency maps in images, attention weights in transformers, etc.) is making progress. Explainability also helps with debugging models – if we know why a model made an error, we can fix it (perhaps the model focused on the wrong cues, like a pneumonia detector focusing on a hospital watermark in X-rays – yes, that happened, as the watermark inadvertently correlated with positive cases). As ML gets deployed widely, explainable AI is crucial for accountability and trust. In fact, IBM has a nice description: “Explainable AI is a set of processes and methods that allows human users to comprehend and trust the results and output created by machine learning algorithms.”. This trust is indispensable in sectors where lives or livelihoods are affected.
- Accountability and Safety: Beyond the big three above, there are other ethical angles. One is accountability – if an AI system causes harm or makes a wrong decision, who is responsible? The developer? The company? The AI itself (can an AI be liable)? This is a hot topic in AI policy and law. For now, generally, companies deploying the model are responsible, which is why thorough testing and risk management for ML is important. Another consideration is robustness and security – ML models can be fooled by adversarial examples (tiny perturbations to input that cause big mistakes) or can suffer from data poisoning (if someone intentionally inserts bad data to skew the model). Ensuring models are robust to such manipulation is both a safety and an ethical issue (especially if ML is used in security contexts). AI Safety in a broader sense is also discussed in context of very advanced AI – ensuring that as AI systems become more autonomous, they act in alignment with human values and do not inadvertently cause harm (this ranges from immediate concerns like a content recommendation algorithm promoting extreme content because it maximizes clicks, to long-term concerns about superintelligent AI). Many top researchers are calling for incorporating ethical principles from the start when designing ML systems.
To address these concerns, various guidelines and frameworks for Responsible AI have been proposed by governments and organizations. For example, the EU’s draft AI Act is proposing regulations especially for “high-risk AI systems” requiring risk assessments, documentation, and human oversight. Companies like Google, Microsoft, and IBM have their AI ethics principles (often covering fairness, privacy, transparency, etc.) and review boards. There’s an increasing demand for AI Explainability and Fairness tools – indeed, IBM’s AI Fairness 360 and Explainability 360 toolkits are examples of practical resources for developers to check bias and explain models. Also, interdisciplinary collaboration is growing – ethicists, social scientists, and domain experts are getting involved in ML projects to foresee and mitigate potential issues.
In summary, ethical considerations are now a central part of the machine learning conversation. Data is about people, and ML outcomes affect people, so we must ensure these systems respect privacy, treat people fairly, and operate transparently. As ML practitioners, it’s no longer enough to chase accuracy metrics; we also ask questions like: “Is my model equitable? Is it interpretable? What are the potential negative consequences of its use?” Balancing innovation with responsibility is the key to ML’s future.
Speaking of the future, let’s conclude with a look at where Machine Learning is headed. What trends are emerging, and how might ML continue to shape industry and society in the coming years?
The Future of Machine Learning
What does the future hold for Machine Learning? Given the rapid pace of advancement, even a few years can bring transformative changes. In this final section, we’ll discuss some expected trends, research directions, and industry impacts for ML in the near and slightly longer term. While predicting the future is tricky, current signs point to several developments:
- Even More Ubiquitous ML (AI Everywhere): Machine Learning is likely to become even more embedded in everyday life. We’ll see “smart” capabilities added to countless products and services. Edge computing and TinyML will enable ML to run on small devices (IoT sensors, microcontrollers) with low power – imagine farm sensors that use ML on-device to detect crop diseases, or your home appliances optimizing their energy usage autonomously. As hardware advances, the dichotomy of cloud vs edge will blur; many devices will run local models for speed and privacy, collaborating with larger cloud models when needed. Voice assistants and AR/VR interfaces will become more natural and context-aware, potentially acting as always-on personal aides. Essentially, ML will become like electricity – quietly integrated, often invisible, but powering functionalities everywhere.
- AutoML and Democratization Continue: The trend of making ML easier to use will accelerate. No-code or low-code ML platforms are growing, letting people build models via visual interfaces or simple scripts. This democratization means more people in non-computing fields can leverage ML for their needs (think biologists using AutoML to classify cell images without needing to write code). As a result, we might see an explosion of domain-specific ML applications crafted by domain experts rather than ML experts. Additionally, pretrained models and APIs for common tasks (vision, language, etc.) will proliferate, so one doesn’t need to reinvent the wheel. Just like today, a lot of software development is plugging into APIs, similarly, many ML solutions will involve plugging into existing models. This also means a commoditization of certain ML capabilities – the differentiation might shift to data (who has the best data) and how you use the predictions (product integration and user experience), rather than the model itself.
- Integration of ML with Other Fields: One exciting direction is the combination of ML with other AI approaches and beyond. Neuro-symbolic AI attempts to integrate neural networks (pattern recognition) with symbolic reasoning (logic, knowledge graphs) to get the best of both worlds – the flexibility of learning from data with the rigor of logical rules and reasoning. This could help AI not just recognize patterns, but reason and extrapolate better (for example, solving math word problems by combining learned text understanding with a symbolic solver). Cognitive AI looks at incorporating aspects of human cognition beyond pattern recognition, like common sense knowledge, reasoning, and planning – some of this will likely involve ML working alongside knowledge bases or simulation. Additionally, ML will increasingly aid scientific research (a trend sometimes called AI for Science): we saw AlphaFold crack protein folding; we can expect ML to help design materials (finding new alloys or chemicals with desired properties), optimize fusion reactor settings, or even assist in proving mathematical theorems by spotting patterns or conjectures. In turn, concepts from these fields might inspire new ML techniques (e.g., physics-inspired neural networks that conserve energy or symmetry).
- Regulation and Standards: As ML becomes more critical in decisions that affect lives, there will be more government oversight. We can anticipate regulatory frameworks solidifying. The EU’s AI Act, once in effect, will likely influence global standards (much like GDPR influenced data privacy practices worldwide). We might see something akin to “FDA for algorithms” in healthcare, requiring clinical trial-like evaluation for AI diagnostic tools. Standards for auditing AI (for bias, performance, robustness) could become part of compliance. Companies might need to maintain detailed documentation for their models (who collected the data? how was the model validated? etc.). While some fear regulation could slow innovation, thoughtful rules can increase public trust and prevent worst-case scenarios. Ethics and responsible AI teams will be a fixture in organizations deploying ML to align with these expectations and regulations. Overall, expect a future where shipping an ML model will require as much careful testing and certification as releasing a new airplane component or a new drug in certain high-stakes domains.
- Focus on Data (Data-Centric AI): A phrase gaining traction (championed by Andrew Ng) is that the next wave of progress might come from focusing more on data quality rather than just algorithmic tweaks. Many organizations have realized that improving the training data (through better labeling, curating more diverse examples, and reducing noise) can yield bigger gains than squeezing another 0.1% from a model’s architecture. We might see improved tools for dataset management, synthetic data generation (using ML to create additional training examples where real data is scarce, while preserving privacy), and techniques for continuous learning as new data comes in (so models stay up-to-date). Better data will also help models be less biased and more robust. “Data is the new oil,” as they say – the companies with high-quality, domain-specific data will have a competitive edge, and there will be an industry around refining that “oil” for ML consumption.
- Continued Advancements in Deep Learning and AI Research: On the research frontier, some people are aiming for Artificial General Intelligence (AGI) – a more general, human-level reasoning machine. Whether that’s achievable with scaling up current methods or requires new paradigms is hotly debated. In the near term, we will likely see more multimodal models (like GPT-4 taking images and text, future models might combine text, vision, audio, and more seamlessly). These models could lead to AI that understands context more like humans do (e.g., you could show a cooking assistant a picture of your fridge contents and have it suggest recipes through voice). Reinforcement learning combined with these powerful models could yield AI agents that can proactively take actions in software or in the physical world (OpenAI’s ChatGPT, for example, can be seen as an agent that interacts through text). We’ve already seen glimpses: an RL + language model that can schedule its chain of thought or call external tools to solve problems. Some talk about AI “agents” that could do tasks for you (schedule appointments, do shopping, troubleshoot IT issues by sequentially interacting with systems) – ML is the core of enabling that autonomy. In robotics, advances in RL and sim-to-real transfer might finally bring about more reliable robots in daily life (for elder care, cleaning, delivery drones, etc.). Quantum machine learning is another area of research – if practical quantum computers arrive, they might speed up certain ML computations or enable new types of models, but that’s still speculative at this stage.
- Industry and Workforce Impact: ML and automation do raise the question of job impacts. The future will see some roles being augmented or even replaced by ML-driven automation (for instance, routine data analysis or report generation might be automated, some customer service roles might be handled by chatbots, etc.). However, it will also create new roles – the so-called “AI economy”. There will be demand for ML engineers, data curators, AI ethicists, etc., as well as entirely new services and products emerging that we can’t fully predict (10 years ago, who anticipated the role of a “prompt engineer” for interacting with language models?). The workforce might need to shift towards tasks that require human strengths like creativity, complex strategic planning, or emotional intelligence, letting ML handle repetitive or data-heavy tasks. Ideally, ML becomes a collaborator – e.g., doctors with AI diagnostic assistants (the doctor focuses on patient interaction and final decisions, while the AI handles image scans), teachers with AI tutoring tools (the teacher provides guidance and personal touch, AI handles drilling practice and personalized content), etc. The companies that leverage ML effectively will likely outcompete those that don’t, similar to how computer-adopting companies had an edge in the past. So, AI literacy will become important for many professions – understanding what ML can and cannot do, and knowing how to work with AI tools.
- Generative AI and Creative Applications: Given the boom in generative models, we’re going to see a lot more AI-generated content. This will blur lines in entertainment and media – AI-generated art, music, and writing will be commonplace. This raises its questions (how do we value human-made art? how to detect deepfakes and ensure authenticity?). But from a technology standpoint, expect generative models to keep improving. We might get to a point where, say, a single sentence like “create a 10-minute video of a medieval fantasy battle scene” could be turned into a pretty convincing video by an AI. This could revolutionize content creation, making it faster and more accessible. On the flip side, it also means we need better ways to verify what is real (the classic concern about fake news and deepfakes spreading misinformation). This is an area where ML again helps – creating fakes and also detecting fakes (discriminator models or forensic tools).
To wrap up, the future of Machine Learning is bright, but it will require careful navigation. We can expect ML to further transform industries, solve problems once thought unsolvable, and perhaps even shift how we interact with technology on a fundamental level (with AI becoming more of an interactive partner than a mere tool). At the same time, ensuring ML is used responsibly and for the benefit of all is an ongoing challenge. Trends like AutoML, transfer learning, and ever-more-powerful models will make ML more powerful and widespread. As of now (the mid-2020s), we stand at a point where ML is moving from a nascent, niche technology to a mature force driving innovation across the board. Just as the internet in the early 2000s went from something new to something that underpins everything, Machine Learning is on that trajectory.
In conclusion, Machine Learning has grown from a theoretical concept to an indispensable technology in a few decades. We’ve covered its definition, traced its history from early perceptrons to today’s deep learning breakthroughs, examined how it works under the hood, and looked at the myriad ways it’s applied in the real world. We also discussed how to ensure ML models are built and used ethically, and speculated on what’s next. The journey of ML is far from over – in fact, it feels like it’s just beginning, with much more to come. For anyone learning ML today, it’s an exciting field with opportunities to make a positive impact by building smarter systems. As ML continues to evolve, one thing remains clear: Machine Learning will be a key driver of innovation in the years ahead, and understanding it, even at a high level, is becoming essential for navigating the modern world. Whether you end up developing ML algorithms or simply using AI-powered products, being informed about Machine Learning empowers you to better engage with the technologies shaping our future.

