Contents
- What Are Neural Networks NL? The Core Technology Behind Modern Artificial Intelligence
- From Perceptrons to Deep Learning: A Brief History
- How Neural Networks Work: NL- Core Concepts
- Popular Neural Network NL Architectures
- Feedforward Neural Networks NL (FNNs)
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM) Networks
- Transformers and Attention Mechanisms
- Applications of Neural Networks Across Domains
- Marketing and Personalization
- Healthcare and Medical Imaging
- Finance: Fraud Detection, Trading, and More
- Current Challenges and Limitations
- Future Trends and Research Directions
- Conclusion
What Are Neural Networks NL? The Core Technology Behind Modern Artificial Intelligence
Neural networks are computational models inspired by the human brain, built from layers of interconnected neurons (nodes) that learn to recognize patterns in data. In modern artificial intelligence, neural networks have become foundational – they power everything from image recognition and speech translation to recommendation systems and self-driving cars. What makes neural networks so pivotal is their ability to learn from examples and improve over time, uncovering complex relationships that were previously hard to program by hand. In this comprehensive blog, we will explore what neural networks are and why they matter, trace their historical evolution from the early perceptron to today’s deep learning revolution, explain core concepts (like weights, biases, activation functions, forward/backpropagation), survey popular architectures (FNNs, CNNs, RNNs, LSTMs, Transformers), highlight real-world applications in marketing, healthcare, and finance, provide pseudocode to illustrate implementation, discuss current challenges (such as interpretability and data needs), and glimpse future trends in neural network research.
From Perceptrons to Deep Learning: A Brief History
The story of neural networks began in the late 1950s. Psychologist Frank Rosenblatt introduced the perceptron in 1957, often hailed as the first artificial neural network. The perceptron was a simple model of a neuron: it took several binary inputs, computed a weighted sum, and produced an output of 1 if the sum exceeded a threshold (and 0 otherwise). Rosenblatt’s early perceptron machine garnered massive excitement – newspaper headlines even claimed it was an “embryo” of a computer that could learn and be conscious. Indeed, Rosenblatt boldly envisioned a machine that could “perceive, recognize, and identify its surroundings without any human training or control”.
However, progress soon slowed. In 1969, Marvin Minsky and Seymour Papert published the book Perceptrons, which proved a fundamental limitation: a single-layer perceptron cannot learn certain simple functions like the XOR (exclusive OR) problem. They showed that perceptrons could only solve linearly separable tasks and lacked the power to handle more complex patterns. This result, combined with general skepticism, led to a decline in neural network research through the 1970s – a period sometimes called the first “AI winter”. Funding dried up, and many researchers shifted focus, believing neural nets had hit a dead end.
Research revived in the 1980s with the introduction of multi-layer neural networks and a learning algorithm called backpropagation. Scientists realized that stacking neurons into additional hidden layers could overcome perceptron limitations. The key was to find a way to train these multi-layer networks. In 1986, Rumelhart, Hinton, and Williams published a landmark paper detailing the backpropagation algorithm. Backpropagation allowed networks to adjust weights in all layers, not just the last, by efficiently propagating the error gradient backwards from the output to each connection. In essence, the network’s prediction error was computed at the output and then fed backward through the network using calculus (the chain rule), guiding how each weight should be nudged to reduce the error. This breakthrough demonstrated that multilayer perceptrons could learn complex tasks that single-layer networks could not, reigniting interest in neural nets.
By the late 1980s and 1990s, neural networks began tackling real-world problems. Yann LeCun and others developed convolutional neural networks (more on CNNs later) like LeNet to read handwritten digits, which were used by banks to recognize check numbers by the mid-90s. Neural nets were also applied to early speech recognition and simple sequence tasks. However, other methods (like support vector machines) often rivaled neural nets in these decades, and training deep networks was hard with the limited computing power.
The true deep learning revolution took off in the 2000s and early 2010s. Three factors combined to supercharge neural networks: (1) much greater computing power (especially the use of GPUs for parallel processing), (2) the availability of massive datasets for training, and (3) innovations in network architectures. In 2012, a watershed moment came when a deep convolutional network called AlexNet (designed by Alex Krizhevsky and colleagues) blew away the competition in the ImageNet image recognition challenge. AlexNet’s stunning performance – achieving far lower error rates than previous approaches – was an “early catalytic event” that ignited the current AI boom. From that point on, deep neural networks (meaning networks with many layers) rapidly became the go-to approach in AI for vision, speech, and beyond.
Subsequent years saw neural networks conquer task after task. In the early 2010s, recurrent neural networks (RNNs) and their variant LSTMs started to achieve state-of-the-art results in sequence modeling problems like speech recognition and language translation. The Long Short-Term Memory (LSTM) network, invented by Hochreiter and Schmidhuber in 1997, introduced a gated architecture that overcame the “vanishing gradient” problem plaguing standard RNNs, enabling networks to learn long-range time dependencies. By around 2016, LSTM-based networks were powering things like Google’s machine translation system, demonstrating fluent translations by processing entire sentence sequences rather than word-by-word with older models.
The latest paradigm shift came in 2017 with the advent of Transformers. Introduced in the paper “Attention Is All You Need,” transformer models eschew recurrence entirely and instead use a mechanism called self-attention to process sequences. This innovation allows them to look at all parts of an input sequence in parallel and weigh the influence of each part on others. Transformers can capture long-range dependencies without the step-by-step recurrence of RNNs, which means they train faster (benefiting from parallel computation) and handle very long sequences more effectively. Transformers quickly became the dominant architecture for natural language processing and are now making inroads in vision and other domains. They form the backbone of powerful large language models like BERT and GPT (Generative Pre-trained Transformer), enabling systems like ChatGPT that can generate human-like text. Today, neural networks are deeper and more capable than ever – some models have billions of parameters – and they continue to drive rapid progress in AI.
How Neural Networks Work: NL- Core Concepts
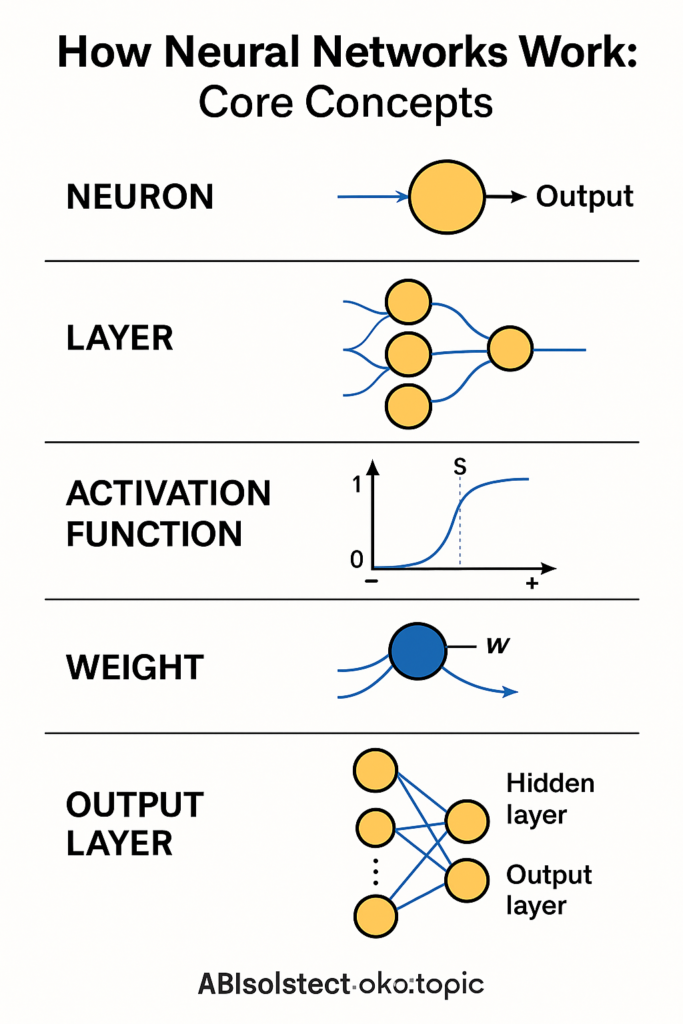 Before diving into specific network types, let’s unpack how a basic neural network functions. The fundamental building block is an artificial neuron, often called a node. An artificial neuron is a simplified model of a biological neuron: it receives one or more inputs, computes a weighted sum of those inputs, adds a bias term, and then applies an activation function to produce an output. Neurons are organized into layers, and the neurons in each layer typically connect to those in the next layer, forming a feedforward network (information moves forward from input to output).
Before diving into specific network types, let’s unpack how a basic neural network functions. The fundamental building block is an artificial neuron, often called a node. An artificial neuron is a simplified model of a biological neuron: it receives one or more inputs, computes a weighted sum of those inputs, adds a bias term, and then applies an activation function to produce an output. Neurons are organized into layers, and the neurons in each layer typically connect to those in the next layer, forming a feedforward network (information moves forward from input to output).
- Weights and Biases: Every connection between neurons has an associated weight, a number that indicates the strength and sign of the influence. A larger weight (positive or negative) means the input is more strongly affecting the next neuron’s output. Each neuron also usually has a bias, which can be thought of as an extra input that is always 1, with a weight (the bias) that shifts the neuron’s overall weighted sum up or down. During learning, the algorithm adjusts weights and biases – these are the parameters that the network “learns” from data.
- Activation Functions: After computing the weighted sum of inputs (plus bias), a neuron applies an activation function f(sum) to yield its output (sometimes called the neuron’s “activation”). The activation function introduces non-linearity, which is crucial. If we only had linear operations, a multi-layer network would collapse into an equivalent single-layer linear model – no more powerful than a perceptron. Activation functions allow networks to model complex, non-linear relationships in data. Early networks used step functions (output 0/1) or smooth functions like sigmoid and tanh (which squish any input to a range like 0 to 1 or 1 to 1). Modern networks often use ReLU (Rectified Linear Unit), which outputs 0 for negative inputs and linear for positive inputs. ReLU is popular because it is simple and mitigates some training issues (it doesn’t saturate for large positive values, so gradients don’t vanish as quickly). There are many other activations (ReLU variants, exponential linear units, etc.), each with pros and cons, but their goal is the same: provide the network with non-linear decision boundaries so it can learn rich behaviors.
- Forward Propagation: When we feed an input into a neural network, it’s processed layer by layer in a forward pass until an output is produced. For example, consider a network with one hidden layer. We input a feature vector x, each input neuron passes its value (or, for the first layer, the input is just the data feature) to the hidden neurons, which compute their weighted sums and activations. Those activations become inputs to the next layer (e.g., the output layer), which does the same calculation to produce final output(s). This process is called forward propagation – signals go forward from the input layer, through any hidden layers, to the output. If the network is being used for prediction (say, classifying an image), the output might be a set of probabilities for each class.
- Loss Function: How do we know if the network’s output is “good”? That’s defined by a loss function (also called a cost function), which measures the error between the network’s prediction and the true target value. For instance, in a regression task, the loss might be the Mean Squared Error between predicted and actual values; in a classification task, a common loss is cross-entropy, which compares the predicted probability distribution over classes to the true distribution (which is 1 for the correct class and 0 for others). The network’s objective is to minimize this loss. During training, after each forward pass, we compute the loss to see how far off the prediction was.
- Backpropagation and Gradient Descent: Once we have the loss, the network learns by updating its weights to reduce that loss. Backpropagation is the algorithm that makes this feasible by efficiently calculating how changes in each weight would affect the loss. In practice, backpropagation works in tandem with an optimization method, typically gradient descent (or one of its variants like Adam, RMSProp, etc.). Here’s how it works: the backpropagation algorithm uses the chain rule of calculus to find the gradient of the loss concerning each weight in the network. The gradient is essentially a sensitivity measure – it tells us, “if you nudge this weight a little up or down, how will it change the loss?” With those gradients, gradient descent then adjusts each weight in the opposite direction of the gradient (since we want to go downhill on the loss surface) by a small amount proportional to a learning rate. In formula terms, if ww is a weight and ∂Loss∂w\frac{\partial \text{Loss}}{\partial w} is its gradient, the update might be:
w:=w − η ∂Loss∂w ,w := w \;-\; \eta \;\frac{\partial \text{Loss}}{\partial w}\,,
Where η\eta is the learning rate (a small positive number). After this update, if the gradients were computed correctly, the loss will be a little bit lower. The network then takes the next training example (or batch of examples) and repeats the forward pass and backprop steps, and so on. Over many epochs (passes through the training data), the weights gradually adjust to minimize the loss. This is how a neural network “learns” from data: through iterative refinement of its weights and biases to better fit the examples.
Popular Neural Network NL Architectures
Not all neural networks are built the same way. Depending on the nature of the task (images vs. sequences, for example), different architectures have emerged. Here we describe some of the most popular types:
Feedforward Neural Networks NL (FNNs)
The feedforward neural network NL is the classic architecture we’ve implicitly discussed so far. Sometimes called multi-layer perceptrons (MLPs) or dense networks, feedforward nets consist of an input layer, one or more hidden layers of neurons, and an output layer, with each layer fully connected to the next. Information flows only in one direction – forward – from inputs to outputs. There are no cycles or loops in the network’s connectivity (hence “feedforward”). These networks are general function approximators: given enough neurons and layers, an FNN can approximate virtually any mathematical function to a high degree of accuracy. They are the foundation for many tasks where the data can be represented as a fixed-size vector of features.
Use cases: Feedforward networks are used in tasks like tabular data prediction, basic classification/regression tasks, or as components inside larger models. For example, an FNN can take a set of customer features (age, income, etc.) and predict the likelihood of a purchase. However, when data has a specific structure (like images or sequences), specialized architectures (CNNs, RNNs) tend to perform better by exploiting that structure.
Convolutional Neural Networks (CNNs)
If you’ve heard about deep learning breakthroughs in computer vision, you’ve likely heard of CNNs. Convolutional Neural Networks are designed to process grid-like data, most notably, images (which can be seen as 2D grids of pixels). A CNN introduces two key ideas: local receptive fields and shared weights (filters). Instead of every neuron seeing all inputs (as in a fully-connected layer), neurons in a convolutional layer only connect to a small patch of the input image (for instance, a 5×5 region of pixels). This localized connection is called a receptive field. The same set of weights (called a filter or kernel) is slid over different positions of the image, performing a convolution operation. Essentially, this means the network is learning filters that detect features like edges, textures, or shapes, and these filters are applied across the entire image. This gives CNNs two big advantages for images: spatial locality (they learn from local pixel patterns) and parameter sharing (the same feature detector is used in multiple places), which drastically reduces the number of parameters needed and makes learning more efficient.
A CNN typically consists of one or more convolutional layers (often followed by a non-linear activation like ReLU), sometimes interleaved with pooling layers that downsample the feature maps (to make the representation more scale-invariant and to reduce computation). After a few such layers, a CNN usually ends with some fully-connected layers to produce the final classification or output. CNNs became famous when LeCun’s LeNet-5 successfully read handwritten digits, and later when AlexNet and subsequent architectures (VGG, ResNet, etc.) kept pushing the state of the art in ImageNet competitions. Today, CNNs excel at tasks like image classification, object detection, and image segmentation, any task involving visual data.
To illustrate, consider image classification: the first conv layer might learn simple features (edges at various orientations), the next layer might combine edges into motifs (corners, contours), further layers assemble motifs into parts of objects, and eventually, some layer can recognize whole objects. This automatic hierarchical feature learning is a hallmark of CNNs, and it’s why they outperform older computer vision methods that relied on hand-engineered features. In summary, CNNs are specialized neural networks for visual data: they leverage convolution operations to learn spatial hierarchies of features, making them extremely effective for image and video analysis.
Recurrent Neural Networks (RNNs)
While CNNs handle images well, Recurrent Neural Networks shine on sequential data – data where order matters. This includes sequences like time-series data, text, audio (speech), or DNA sequences. The defining characteristic of an RNN is that it has recurrent connections: the network’s hidden state at one time step feeds into the computation of the next time step. In other words, an RNN processes one element of the sequence at a time (one word, one time-step, etc.), and it maintains a memory of what’s come before by way of its internal state. This allows it to capture temporal dependencies – the influence of earlier parts of the sequence on later parts.
In a simple RNN, at each time step tt, the network takes an input xtx_t and the previous hidden state ht−1h_{t-1}, and produces a new hidden state hth_t (and possibly an output). The recurrence can be thought of like a loop unrolled in time: ht=f(W⋅xt+U⋅ht−1)h_t = f(W \cdot x_t + U \cdot h_{t-1}), where ff is an activation function (like tanh) and W,UW, U are weight matrices for input and recurrent connections respectively. Because of this recurrence, an RNN can, in theory, retain information from many steps past – it builds an internal representation of the sequence as it goes.
Uses of RNNs: RNNs are natural for language modeling (predicting the next word in a sentence), machine translation (reading a sentence in one language, one word at a time and then producing a translation), speech recognition (processing audio frame by frame), and any scenario where context matters. For example, to predict the next word in “I grew up in France… I speak fluent ___”, an RNN can carry the context that the country was France, so the likely next word is “French”. Feedforward networks wouldn’t have a straightforward way to incorporate the earlier words, but RNNs handle this sequential context by design.
However, standard RNNs have trouble with long-term dependencies. In theory, they can handle very long sequences, but in practice, they struggled to learn relationships that span more than, say, 10 or 20 timesteps due to the vanishing gradient problem (gradients tend to get very small or very large when backpropagated through many time steps). This meant long-range context (like something mentioned paragraphs earlier in a text) was hard to learn.
Long Short-Term Memory (LSTM) Networks
To address the limitations of basic RNNs, researchers developed improved recurrent architectures. The most famous is the Long Short-Term Memory (LSTM) network. LSTM was introduced in the late 1990s and specifically designed to remember information for long durations. It did so with an ingenious gating mechanism. Each LSTM cell contains a set of gates – often called the input gate, forget gate, and output gate – that regulate the flow of information. These gates can learn to decide how much of the past to keep or forget. For instance, the forget gate can learn to reset the cell’s state if old information is no longer needed, preventing irrelevant older data from cluttering the memory. The input gate controls what new information to store in the cell state, and the output gate controls how much of the cell state to reveal as output.
Importantly, LSTMs carry a cell state (sometimes thought of as the long-term memory) that runs straight through the cell with only some linear interactions, which makes it easier for information (and gradients) to flow unchanged over long time intervals. This architecture enables LSTMs to capture long-range dependencies far better than standard RNNs. In practice, LSTMs (and the related simpler GRUs, Gated Recurrent Units) became the go-to for sequential tasks throughout the 2000s and 2010s. An LSTM can handle sentences or sequences where the critical information might have occurred much earlier in the sequence.
For example, in text analysis: “The series that the critics praised so much was cancelled after one season.” – to predict a word referring to “the series” later, the network might need to remember the subject from the beginning of the sentence. LSTMs are much better at this kind of long-distance relationship than vanilla RNNs.
Transformers and Attention Mechanisms
The newest generation of neural network architecture is the Transformer, which has taken the machine learning world by storm in recent years. Transformers were first developed for translation and language tasks, but their use has expanded to many domains. The core innovation of the Transformer is the self-attention mechanism (also known as intra-attention). Instead of processing sequences iteratively like an RNN, a transformer processes the entire sequence (or large chunks of it) in parallel, and for each element, it uses self-attention to weigh its relevance to other elements in the sequence. In simpler terms, the model learns to “pay attention” to certain parts of the input when producing each part of the output.
For example, in translating a sentence, when generating the translation for a word, a transformer’s attention mechanism might focus on the relevant words in the source sentence regardless of their distance. The attention mechanism computes a set of attention weights that determine how much each other position in the sequence should influence the current position’s representation. Multi-head attention (multiple sets of attention working in parallel) allows the model to capture different types of relationships (e.g., syntax, coreferences, etc.) simultaneously.
Transformers typically have an encoder-decoder architecture: an encoder reads the input sequence and produces a set of contextual embeddings, and a decoder generates the output sequence (for tasks like translation or language modeling). However, many tasks only require the encoder part (e.g., text classification or generating image embeddings), and some models like GPT use only the decoder part for generative tasks.
The big advantages of transformers are: (1) Parallelization – since they don’t have to go one step at a time, they can be trained on very large sequences using parallel GPU operations (the self-attention can be computed for all pairs in a sequence in matrix form). (2) Long-Range Capability – with attention, even if two words are far apart, the model can directly connect them if needed (whereas an RNN might have to carry information through many steps). (3) Scalability – researchers found that making transformers bigger (more layers, more attention heads, more data) keeps yielding better performance, leading to the era of extremely large models.
Transformers have quickly become state-of-the-art for natural language processing tasks and are also being applied to vision (the Vision Transformer or ViT applies transformer architecture to image patches instead of pixels), to audio, and even to reinforcement learning problems. They are the engines behind large language models like GPT-3, GPT-4, BERT, and others, which are trained on enormous text corpora and can generate coherent text, translate languages, answer questions, and more. The impact of transformers has been enormous – for instance, GPT-based models have shown unprecedented capabilities in generating human-like text, and multi-modal transformers are starting to handle tasks that involve text + images together.
It’s worth noting that while transformers solved many sequence modeling issues, they come with their challenges – chiefly, the self-attention mechanism has a computational cost that scales quadratically with the sequence length (because every pair of positions is compared). This can make extremely long sequences costly to handle, and there’s active research on making transformers more efficient for long inputs (using techniques like sparse attention, landmarks, etc.). Still, the versatility and superior performance of transformers have cemented them as a key architecture in the deep learning toolbox.
In summary, today’s landscape is rich: for images and spatial data, we use CNNs; for sequential data, we historically used RNNs/LSTMs, but now often use Transformers; and plain feedforward networks are employed for simpler tasks or as final prediction layers. Often, these components are combined – e.g., an image captioning system might use a CNN to encode an image and a Transformer decoder to generate a caption. Neural network architectures can be mixed and matched depending on what the AI system needs to do.
Applications of Neural Networks Across Domains
One reason neural networks are so celebrated is that their applicability spans virtually every field. Anywhere there is data, a neural network can potentially learn from it. Here are a few notable domains and how neural networks are making an impact:
Marketing and Personalization
In the marketing world, understanding and catering to individual customers is gold. Neural networks help businesses analyze vast customer datasets to perform customer segmentation, predict customer behavior, and deliver personalized experiences. For example, deep learning models drive recommendation systems on e-commerce and streaming platforms: Amazon’s product recommendations or Netflix’s movie suggestions are powered by neural networks analyzing your past behavior to suggest what you’ll likely buy or watch next. In digital advertising, neural networks predict which ads you’re most likely to click, enabling targeted advertising tailored to your interests.
Retailers also use neural nets for customer lifetime value prediction, churn prediction (identifying which customers are likely to stop using a service, so they can intervene), and even dynamic pricing strategies. A specific example is how online services cluster users into segments – neural networks (including unsupervised variants or autoencoders) can find patterns in user behavior and demographics to group similar customers, helping marketers tailor strategies to each group.
Neural networks truly excel at personalization because they can model very complex interactions in data. A deep learning recommendation model might take into account not just straightforward features like age or location, but also your detailed browsing history, past purchases, product similarities, and even textual reviews or images of products you liked. Models like Deep Learning-based Collaborative Filtering and sequence-based recommenders (which treat a user’s viewing history as a sequence) are giving more accurate results than ever before. The result for the consumer is that the content or offers they see feel hand-picked and relevant.
In summary, neural networks in marketing help companies move from one-size-fits-all approaches to personalized customer experiences at scale – something that would be impossible with manual analysis. According to industry reports, many financial and retail institutions deploy neural networks for customer experience (like recommendation and personalization tools) as well as for security and risk management. This has led to higher engagement, improved customer satisfaction, and better ROI on marketing campaigns.
Healthcare and Medical Imaging
Healthcare has been revolutionized by neural networks, particularly in areas like medical imaging and diagnostics. Deep neural networks (especially CNNs) have shown an extraordinary ability in analyzing medical images, whether it’s X-rays, MRIs, CT scans, or retinal photos. For instance, neural networks can learn to detect tumors, fractures, or diseases in images as well as or even better than human specialists in certain tasks. Several studies have found that AI models (usually CNN-based) achieve diagnostic performance comparable to medical experts in image recognition tasks like detecting diabetic retinopathy in eye scans or classifying skin lesions from dermatology photos. In 2018, a deep learning algorithm famously matched dermatologists at identifying skin cancer from images, and another matched radiologists in spotting pneumonia on chest X-rays. Such models are now being developed to assist or triage medical decision-making, potentially catching diseases earlier or in places with a shortage of specialists.
Beyond imaging, neural networks are used in analyzing electronic health records (for predicting patient outcomes or identifying risk factors), in genomics (for example, deep learning models can predict how likely a DNA sequence is to have certain properties, or identify gene expressions linked to diseases), and even in drug discovery (models predict how different molecules will interact, or identify potential new drug candidates from large chemical databases). Recurrent models and transformers are used to analyze medical texts or biomedical literature to stay on top of new research findings.
Another burgeoning area is personalized medicine: using neural nets to predict which treatment strategies might be most effective for a specific patient, given their unique profile. For example, in oncology, models are being trained on past cases to predict how a tumor might respond to a certain chemotherapy based on its genetic markers.
In summary, neural networks in healthcare aim to augment the capabilities of doctors by providing tools that can quickly and accurately analyze complex medical data. They are improving diagnostic accuracy and consistency, helping flag critical cases faster, and mining insights from patient data that would be hard to uncover manually. Of course, these tools have to be vetted thoroughly – in life-and-death matters, trust and transparency are key (we’ll talk about challenges like interpretability soon) – but the potential to improve patient outcomes and democratize expertise (e.g., having an AI assist in places where experienced radiologists are not available) is truly exciting.
Finance: Fraud Detection, Trading, and More
The finance industry was one of the early adopters of neural networks back in the 1980s and 90s, using them for things like credit scoring and stock market prediction. Today, neural networks are deeply entrenched in finance for a variety of purposes, thanks to increased data and computing power.
One critical application is fraud detection. Banks and credit card companies face massive volumes of transactions and have to pinpoint the handful that are fraudulent. Neural networks (including newer approaches like Graph Neural Networks that look at networks of transactions) are used to detect anomalous patterns that may indicate credit card fraud, money laundering, or other illicit activities. Because fraudsters constantly evolve their tactics, the adaptive learning ability of neural models is very valuable – they can be retrained on recent data to catch new patterns of fraud. Models examine factors like spending behavior, device data, location, and more to flag suspicious activity, often in real time. The 90s saw early neural nets for fraud detection (e.g., for credit card transactions), but they were limited by hardware; today’s deep networks are far more powerful and can ingest larger streams of data with higher accuracy.
Another major area is algorithmic trading and finance prediction. Hedge funds and trading firms use deep neural networks to analyze market data and news feeds to inform trading decisions. Recurrent networks or transformers might process sequences of stock prices (time series) to predict future trends or detect signals. Some approaches use reinforcement learning (where the “agent” learns to trade by maximizing return in a simulated market environment) – famously, there have been experiments with neural networks learning to execute trades or manage portfolios. Neural networks are also used in portfolio management to optimize asset allocations, balancing risk and return.
In risk management, banks use neural nets to model and predict risks like the probability of default on loans (credit risk modeling) more accurately than traditional linear models. They also use them for stress testing and scenario analysis, where complex interdependencies might exist in the financial system.
Customer-facing finance also benefits: for example, chatbots and virtual assistants for banking queries often use neural language models to interact with customers. Banks also personalize product recommendations (much like e-commerce), suggesting financial products to customers using predictive models that analyze customer data. In operations, neural networks help in automating document processing (like reading checks or contracts), which overlaps with the text/image capabilities mentioned earlier.
Security is paramount in finance, so neural networks are used in fraud and cybersecurity (flagging unusual server/network activity that might indicate a cyber attack).
In summary, neural networks bring a combination of predictive accuracy and adaptability that’s invaluable to finance. They are used in “numerous operational domains” in financial institutions – from risk management (predicting market volatility, credit defaults) to customer experience (chatbots, personalization), security (fraud detection, anti-money laundering), operational efficiency (automation of processes), and trading/investments (algorithmic trading strategies and portfolio optimization). The banking sector has fully embraced AI, with global spending on AI in banking projected to reach tens of billions in the coming years. Neural networks, as the backbone of many AI solutions, are driving much of this transformation.
These are just a few domains – we could equally talk about how neural networks are used in manufacturing (for predictive maintenance by analyzing sensor data from machines), transportation (autonomous driving relies heavily on CNNs for vision and neural networks for decision making), education (personalized learning tutors), agriculture (crop disease detection from images, or optimizing yield with predictive models), and so on. The versatility of neural networks means they can model virtually any dataset given enough training data, so new applications pop up constantly.
Current Challenges and Limitations
With all the success stories, it’s easy to think neural networks are a silver bullet. But in practice, developing and deploying neural network solutions comes with several challenges and limitations that are important to understand:
- Data Hungry: Neural networks typically require a lot of data to train effectively, especially deep networks with many parameters. Training data needs to be not only large in quantity but also representative of the real-world scenarios the model will face. In domains where data is scarce or expensive (e.g., labeled medical data), this poses a big challenge. If a neural net is trained on insufficient or low-quality data, it may either fail to learn useful patterns or learn spurious ones that don’t generalize (overfitting).
- Computationally Intensive: Training large neural networks is computationally demanding. It often requires specialized hardware like GPUs or TPUs and can take hours, days, or even weeks of computation. This makes it costly and energy-intensive. Even after training, running these models (inference) can be heavy, especially for real-time applications or on edge devices with limited resources. There is ongoing work on model compression (pruning, quantization) and more efficient architectures to mitigate this, but it remains a concern. Not every organization has the resources of Google or OpenAI to train multi-billion parameter models.
- Lack of Interpretability (Black Box Nature): One of the most cited issues is that deep neural networks are often black boxes – they don’t readily explain why they made a certain decision. If a neural network predicts that a patient has a high risk of disease or declines a person’s loan application, it’s not straightforward to extract a human-understandable explanation from the network’s weights. This interpretability problem is crucial in fields like healthcare and finance, where decisions must be transparent for ethical and legal reasons. Researchers are developing techniques for Explainable AI (XAI), such as saliency maps (highlighting which parts of an image most influenced a CNN’s decision) or local explanation methods like LIME and SHAP for general models, but achieving true interpretability is still an open challenge. The lack of interpretability affects trust – users and stakeholders may be wary of relying on a system they don’t understand.
- Overfitting and Generalization: Neural networks have millions of parameters and are extremely flexible. This also means they can overfit the training data – essentially memorizing it – and then fail to generalize to new inputs. Preventing overfitting requires techniques like regularization (e.g., dropout, weight decay), careful architecture choices, and lots of training data augmentation. Despite best practices, there’s always a risk that a model performs impressively on test benchmarks but then encounters unexpected inputs in the wild and makes mistakes. Ensuring robust generalization is an active area of research (including things like adversarial training, which we’ll mention next).
- Adversarial Vulnerabilities: Surprisingly, neural networks can be too sensitive to input changes in ways that fool them. An adversarial example is an input altered very slightly (often imperceptibly to humans) that causes the network to make a wrong prediction with high confidence. For example, adding a barely visible noise pattern to an image of a panda can make a CNN classify it as a gibbon with high certainty; or a slight perturbation to a stop sign image might fool a self-driving car’s vision system into thinking it’s a speed limit sign. These adversarial attacks expose a weakness: neural nets often don’t truly “understand” the input and can be tripped up in ways that humans wouldn’t. This is worrying for security-critical applications, and defending against adversarial attacks is an ongoing challenge. Methods like adversarial training (training on perturbed data) can help, but it’s something practitioners must be aware of.
- Bias and Ethical Issues: Neural networks learn from data, and if that data contains human biases or reflects historical inequalities, the models can inadvertently amplify bias. There have been cases of AI models in hiring, criminal justice, or credit scoring that were found to be biased against certain groups because of biased training data. Ensuring fairness in AI models is a critical challenge. It’s not just about the data – sometimes the way a model is used can raise ethical questions (e.g., deepfake generation, privacy concerns from models that can inadvertently remember training data). There is a growing emphasis on ethical AI, which includes auditing models for bias, having bias mitigation strategies, and ensuring compliance with regulations (like GDPR for data privacy).
- Hyperparameter Tuning: Neural networks come with many knobs to tune – learning rates, number of layers, number of neurons, activation choices, etc. Finding the optimal hyperparameters can be a bit of an art. Researchers and engineers often spend a lot of time experimenting to get the best performance, which is time-consuming and requires expertise. Automated methods (AutoML, Bayesian optimization) are being developed to ease this, but it’s still a non-trivial part of the work.
- Scalability and Deployment: As models get larger (we now have models with billions of parameters), deploying them in real-world settings becomes challenging. Running a huge model on a user’s smartphone, for example, might be impossible due to memory and compute constraints. Even deploying on servers can be expensive. There’s also the challenge of scaling to many users – if your model is used in a web service by millions of people, it needs to handle that load. Techniques like model distillation (creating a smaller model that approximates the larger one’s behavior) and efficient hardware help, but not every cutting-edge model is practical to deploy widely.
To put it succinctly, deep learning faces significant challenges such as data quality, computational demands, and model interpretability. Issues like ethical bias and adversarial robustness are also top of mind for the field. The community is actively researching solutions: for example, there’s a lot of work on explainable AI (to open up the black box), few-shot learning and transfer learning (to reduce data needs by reusing knowledge from one task to another), and efficient AI (to reduce computation and energy usage). Understanding these limitations is crucial because it sets realistic expectations and guides us on where to focus our improvements.
Future Trends and Research Directions
Neural networks have come a long way, but the journey is far from over. The next few years promise to be just as exciting, with several key trends shaping the future of neural network research and applications:
- Explainable and Interpretable AI: As mentioned, one major push is making neural networks more transparent. Future neural nets may incorporate interpretability constraints or architectures that make their decision process more traceable. We might see widespread use of hybrid models that combine neural networks with symbolic reasoning or rules (sometimes called neurosymbolic AI) – leveraging the pattern recognition of neural nets and the logical structure of symbolic AI to get the best of both worlds (and easier explanations). Already, there’s increasing research into tools that allow humans to query a trained model’s logic or visualize exactly what each neuron represents.
- Neural Architecture Search (AutoML): Designing neural network architectures by hand is time-consuming. A growing trend is to use algorithms to design algorithms – that is, have AI search for optimal neural network structures. Neural Architecture Search (NAS) employs techniques like evolutionary algorithms or reinforcement learning to try out many network designs and find high-performing ones automatically. In the future, many neural networks will likely be at least partially designed by other AI, leading to architectures that might be too complex or unintuitive for a human to have invented. This goes hand in hand with the idea of AutoML and no-code platforms, making it easier for non-experts to deploy neural network solutions.
- Continual and Unsupervised Learning: Most neural nets today are trained once on a static dataset and then fixed. The future will see more continual learning models that can keep learning on the fly, incorporate new data without forgetting the old (solving “catastrophic forgetting”), and adapt to changing environments. Also, while supervised learning (training on labeled examples) has dominated, there’s a big interest in reducing reliance on labeled data via self-supervised or unsupervised learning. For example, large language models are self-supervised (learning from raw text by predicting missing words). We’ll see these techniques extend to other modalities – e.g., vision models learning from millions of unlabelled images by simply predicting parts of images or video models predicting future frames. This could dramatically increase the amount of usable training data.
- Multi-modal and Generalized Models: Humans learn from all senses together; similarly, AI models are increasingly combining data from multiple modalities. We already have models like CLIP from OpenAI that learn a joint representation of images and text. Future neural networks will likely be multi-modal – capable of simultaneously processing text, images, audio, perhaps even video, and other sensor data, to create richer, more context-aware AI. This paves the way toward more general AI systems that aren’t just specialists in one task (like vision or NLP) but can perform many tasks, sometimes called foundation models when they serve as a base for multiple purposes. We see early signs with models like GPT-4, which can process text and images together.
- Scaling and Efficiency: The past few years have had a trend: make models bigger, and they get better (the “scaling hypothesis”). We saw GPT-3 with 175 billion parameters, and newer models pushing even further. While this has yielded impressive capabilities, it’s also unsustainable to just keep blowing up model sizes due to costs. So a dual trend is likely: some researchers will push the envelope on scale (especially organizations with vast resources, perhaps reaching trillion-parameter models trained on diverse data for general AI capabilities), while others will focus on making models much more efficient, achieving the same performance with fewer parameters or operations. Techniques like model compression, sparsity (having a lot of zeros in weight matrices to skip computation), and new architectures (like mixture-of-experts models that dynamically activate only parts of the network as needed) are promising. There’s also hardware advances – new kinds of chips optimized for neural nets, and even neuromorphic computing (hardware that mimics brain spikes) or optical computing for AI may become more prominent if they prove to be faster or more energy-efficient.
- Graph Neural Networks (GNNs) and Beyond: Data that is best represented as graphs (networks of nodes and edges) – such as social networks, molecules (atoms connected by bonds), or knowledge graphs – are being tackled by Graph Neural Networks. GNNs have been a hot research area, and we expect them to gain more adoption in areas like drug discovery (modeling molecular interactions) or financial fraud detection (modeling networks of transactions). They expand the reach of neural networks to data structured in non-grid, non-sequence form.
- Integration with Industry and Edge Deployment: As neural nets mature, they will further integrate into everyday technology. We’ll see more AI at the edge – on smartphones, IoT devices, AR/VR headsets, even in appliances and vehicles – running on-device for privacy and latency reasons. This requires compact, efficient models, so expect more research on TinyML (machine learning on microcontrollers). In industry, AI will continue to transform workflows: from intelligent automation in factories to AI assistants in offices. There’s likely to be more regulatory focus too, meaning aspects like fairness and safety will move from research topics to industry standards.
- Hybrid AI and Causal Reasoning: A longer-term trend is combining neural networks with elements of reasoning and understanding causality. Neural nets are great at pattern recognition, but not inherently structured for logic or understanding cause and effect. Future AI might integrate causal inference approaches to not just see correlations in data but reason about what might happen if conditions change (vital for fields like medicine or policy). We might also see more AI systems that can reason step-by-step (there are already efforts in having language models generate reasoning chains, or using tools within neural models). All of this is toward building more robust, reliable AI that can function in complex real-world scenarios more like human intelligence.
In essence, the next frontier of neural networks will likely involve navigating beyond the current limitations and expanding into new capabilities. Innovations like better unsupervised learning, multi-modal understanding, automated design, and efficiency improvements will shape the neural networks of tomorrow. It’s an exciting time: the rapid progress in this field means what seems cutting-edge today (like large transformers) could look routine in a few years, replaced by even more powerful and efficient techniques.
Conclusion
Neural networks have transitioned from a curious biological metaphor to the driving force of modern AI. We’ve seen how they originated with simple perceptrons and weathered periods of skepticism, only to come back stronger with multi-layer learning and eventually explode into the deep learning era that touches all our lives today. By stacking layers of neuron-like units and letting them learn the features and representations directly from data, neural networks have unlocked solutions to problems once thought unsolvable by machines – whether it’s recognizing images, decoding speech, translating languages, or personalizing recommendations.
In this blog, we covered the foundational concepts that underlie all neural networks: how weighted connections and activation functions allow these models to approximate complex functions, and how algorithms like backpropagation enable them to learn from mistakes. We explored the major architecture types (feedforward, CNN, RNN/LSTM, transformers) and saw that each is tailored to different structures in data, yet all share the same basic principles. We also looked at how these networks are applied in the real world, in domains as diverse as marketing, healthcare, and finance, delivering tangible benefits from automating tasks to discovering new insights.
At the same time, we acknowledged the challenges – the “dark side” of neural nets – including their hunger for quality data, heavy computational needs, opacity, and pitfalls like bias and adversarial examples. These remind us that building AI systems responsibly and robustly is as important as building them to be accurate.
Finally, we gazed forward to where this fast-moving field is headed: towards more explainable, efficient, and broadly intelligent systems. The future of neural networks will likely blur the lines between different AI techniques, combine modalities, and push towards models that are not just powerful but also trustworthy and adaptable.
For the interested reader or the professional looking to deepen their knowledge, the key takeaway is that neural networks are both an art and a science. The science lies in the solid mathematical foundations and algorithms; the art lies in how you design, train, and deploy them to solve real problems. With practice (and maybe the help of some of the automated tools emerging), one develops an intuition for this.
As you continue to explore neural networks, keep experimenting with small models and simple code (like the pseudocode example we included) – building things yourself is the best way to truly grasp how they work. The field of AI is famously hands-on and empirical; each breakthrough often comes from trying new ideas and learning from failures. And given the incredible pace of progress, who knows – perhaps you will contribute to the next big innovation in neural network technology.
Neural networks have given machines the ability to see, hear, and understand in ways that were pure fiction not long ago. They truly are, as we started, the backbone of modern AI, and by understanding them deeply, we empower ourselves to harness and shape this technology for the better. The journey of learning about neural networks is as exciting as what you can do with them, and it’s a journey that’s only just begun for humanity.

